JVM 17 概述以及典型的 GC 调优
JVM 17 的介绍
什么是 JVM?
JVM (Java Virtual Machine) 是一个规范(蓝图)。它定义了字节码该怎么运行、内存该怎么排布,但没规定具体怎么写代码实现。
JVM 与 与 Java 版本是同步演进,每当发布一个新的 Java 版本(如 Java 8, Java 11, Java 17),Oracle 都会同时发布 两份最核心的文档:
- Java Language Specification (JLS):Java 语言规范(规定语法怎么写)。
- Java Virtual Machine Specification (JVMS):Java 虚拟机规范(规定字节码怎么跑)。
说白了,Java 语言规范(JLS)定义了程序员看到的 ‘皮囊’,而 JVM 规范(JVMS)定义了程序运行的 ‘灵魂’。两者版本同步,确保了 Java 这种‘一次编写,到处运行’的承诺在每一个世代都能稳定落地。
JVM 规范实现主要有哪些?
HotSpot:是 Oracle/OpenJDK 开发的工业级实现。它最核心的特性是热点代码探测(Hot Spot Detection)。它会监控程序的运行,发现哪些代码执行最频繁(热点),然后让 JIT(即时编译器)把这些代码直接编译成本地机器码,从而获得极高的性能。Hotsopt 是目前世界上应用最广泛的 JVM 实现,也是 JDK 17 默认内置的引擎。如果 JVM 是 “汽车的设计标准”,那么 Hotsopt 就是 JVM 工业级的 “法拉利的引擎”。
GraalVM:这是另一个极具革命性的 JVM 实现(也可以作为 HotSpot 的插件)。它支持 Native Image(原生镜像)技术,能把 Java 程序直接编译成二进制执行文件,启动速度从秒级降至毫秒级,非常适合云原生 Serverless 场景。
OpenJ9:由 IBM 贡献给 Eclipse 基金会的实现,内存占用通常比 HotSpot 更小,适合资源受限的容器环境。
JVM 17 有哪些主要变动?
JVM 17 是继 Java 8 和 11 之后的第三个长期支持版本。它标志着 Java 正式进入了“云原生与低延迟” 时代。在 JDK 17 中,JVM 彻底移除了过时的垃圾回收器(如 CMS),并将模块化系统(Project Jigsaw)的强封装性推向了极致。
内存布局的本质演变
- 元空间 (Metaspace) 的统治:java 17 完全取代了 Java 8 时代的永久代(PermGen)。JVM 17 将类元数据、常量池等存储在本地内存(Native Memory)中,这意味着只要你的机器物理内存够大,你就几乎不会遇到类元数据溢出的问题,有效避免了因频繁加载类导致的 OutOfMemoryError。
- 栈帧优化与向量计算:引入了 Vector API(孵化阶段),允许 JVM 更高效地利用 CPU 的 SIMD(单指令多数据)指令集,在数值计算性能上有了本质突破。
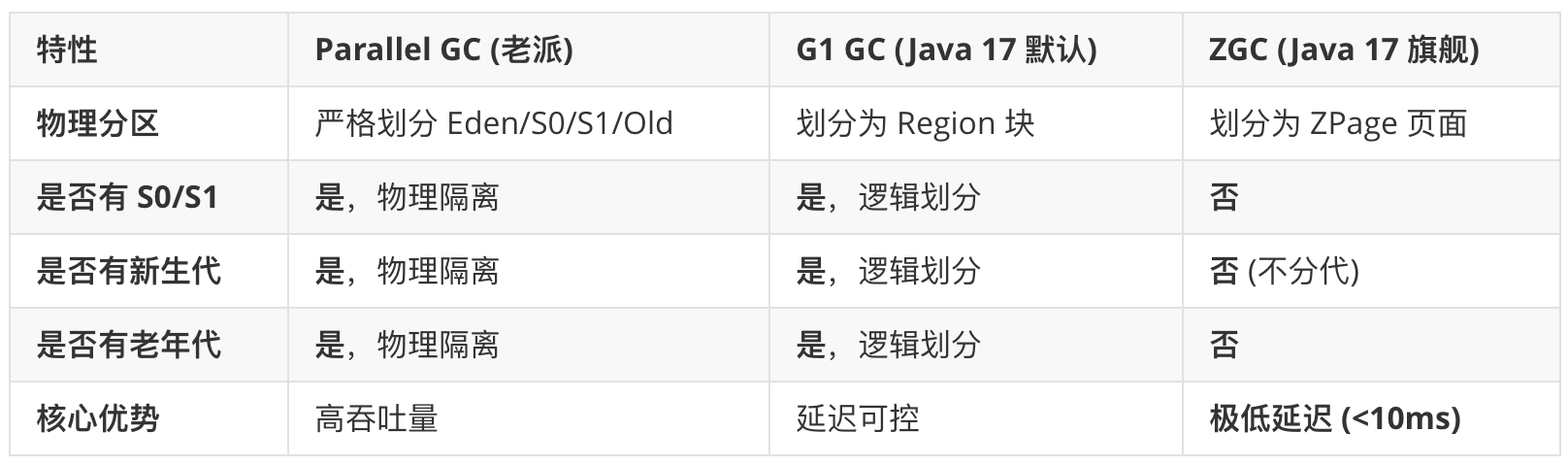
垃圾回收器的 “三足鼎立”
HotSpot VM 内部的三种不同的垃圾回收(GC)算法策略:G1 GC (Garbage First)、ZGC (Z Garbage Collector)、Parallel GC (Parallel Scavenge)。

注:在 JDK 17 中,HotSpot VM 作为核心引擎,通过 G1、ZGC 与 Parallel 三大 GC 策略的精密协作,实现了从高吞吐量到极低延迟的全场景覆盖。特别是正式转正的 ZGC,彻底打破了 Java 内存越大停顿越长的 ‘魔咒’,它通过 “染色指针” 和 “读屏障” 技术,实现了在 10TB 堆内存下 STW(停顿时间)依然小于 1 毫秒。
JVM 17 的运行时数据区
线程私有 (Private)
线程共享 (Shared)
解释执行
C1/C2 即时编译
毫秒级停顿垃圾回收
线程私有区:
这类区域生命周期与线程相同,不存在并发竞争问题。
虚拟机栈:描述 Java 方法执行的线程内存模型,如果栈深度过深会抛出 StackOverflowError;如果申请不到内存则抛出 OutOfMemoryError。每个方法执行时都会创建一个栈帧(Stack Frame),包含以下内容:
- 局部变量表:存放方法参数和方法内的局部变量。
- 操作数栈:执行计算过程中的临时中转站。
- 动态连接:指向常量池中该方法的引用。
- 方法出口:返回地址。
本地方法栈:与虚拟机栈类似,区别在于它是为 JVM 使用到的 Native 方法(通常是 C/C++ 编写)服务的。在 HotSpot VM 实现中,本地方法栈和虚拟机栈往往是合二为一的。
程序计数器:当前线程所执行的字节码的行号指示器。在多线程切换时,确保线程恢复后能回到正确的执行位置。它是唯一一个在 JVM 规范中没有规定任何 OutOfMemoryError 的区域。
线程共享区:
这类区域在 JVM 启动时创建,是内存调优的核心。
堆区:JVM 管理的最大一块内存,几乎所有的对象实例都在此分配内存。Java 17 在 G1 或 ZGC 模式下,堆不再物理上连续划分 “新生代/老年代”,而是逻辑上划分为多个 Region。ZGC 在此区域实现了毫秒级的并发清理。这也是发生 OutOfMemoryError: Java heap space 的重灾区。
元空间(原来的方法区):存储已被虚拟机加载的类型信息、常量、静态变量、即时编译器编译后的代码缓存等数据。是一个逻辑概念。方法区在 JDK 8 以后,其实际实现从 JVM 堆内部的 “永久代” 移到了本地内存中的 Metaspace(元空间),这样的话元空间的大小仅受限于物理内存,减少了因加载类过多导致的 OOM 风险。运行时常量池 是方法区的一部分,存放编译期生成的各种字面量和符号引用。
补充:直接内存 (Direct Memory):
虽然直接内存不属于 JVM 规范定义的运行时数据区,但在现代 Java 开发(尤其是 Netty 等 NIO 框架)中非常重要:
- 机制:通过 Unsafe 或 ByteBuffer.allocateDirect() 直接分配系统内存。
- 优势:避免了在 Java 堆和系统堆之间来回复制数据,极大提高 I/O 性能。
- 典型的案例:
Kafka 零拷贝(Zero-Copy) 机制。kafka 利用了 java.nio.DirectByteBuffer,数据直接在内核缓冲区和直接内存之间传输,甚至通过 sendfile 系统调用直接从磁盘映射到网卡。结果数据不再进入 JVM 堆,省去了从内核态到用户态的繁琐拷贝。Kafka 的高性能秘诀在于:它把 JVM 从一个‘数据搬运工’变成了一个‘指令下达者’。通过 DirectByteBuffer 绕过堆内存拷贝,通过 sendfile 实现零拷贝,让数据在内核中‘贴地飞行’。
注:在 Kafka 的场景下,数据根本不需要进 JVM 堆。第一步:使用 DirectByteBuffer(直接内存),传统 Buffer 是在 JVM 堆里开辟数组,受 GC 管辖,而 kafka 是在操作系统内存里开辟空间。JVM 只是持有一个指向这块空间的 “指针。第二步:通过 sendfile 彻底旁路化,Kafka 调用 Java NIO 的 FileChannel.transferTo() 方法,这在 Linux 底层触发 sendfile 系统调用。这个过程具体是 Kafka(JVM)告诉操作系统:“我要把文件 A 从偏移量 100 开始的 1KB 数据发给 Socket B”。操作系统直接把磁盘里的数据读到内核缓冲区(Page Cache)。操作系统直接把内核缓冲区里的数据拷贝到网卡队列。在这个过程中,数据一次都没有进入过 JVM 的进程空间。JVM 只是下达了一个 “指令”,就像快递公司的老板(JVM)告诉搬运工(操作系统)把仓库里的货直接发走,老板自己根本不碰货。
使用一个案例展示运行时内存
1 | public class Calculator { |
1 | $ javap -c Calculator.class |
java Calculator 时,AppClassLoader 加载字节码。
- Loading: 将磁盘文件读入 Metaspace (元空间)。
- Linking: 验证字节码合法性,为静态变量分配内存。
- Initialization: 执行类初始化代码。
@addr: 0x7af12
aload_1 引向此处。让我们对照 javap 的输出,逐行看指令在内存中的 “跳动”:
- 堆的角色:在 main 方法执行
0: new #7时,JVM 在 Heap (堆) 中分配了一块内存给 Calculator 实例。compute 栈帧局部变量表 0 号槽位的 this,就是指向堆中这个对象的指针。 - 程序计数器:每执行一条指令(如
0: iconst_1),PC 寄存器就会更新为下一条指令的偏移地址(如 1)。它是线程私有的,确保 main 线程在被 CPU 挂起又恢复后,知道从哪一行继续跑。 - 栈中的执行:compute() 核心步骤:
0: iconst_1&1: istore_1: 将常量 1 压入操作数栈,然后弹出并存入局部变量表的 1 号槽位(变量 a)。4: iload_1&5: iload_2: 从局部变量表取出 1 和 2 压入操作数栈。此时栈内 [1, 2](2在栈顶)。6: iadd: 操作数栈弹出两个数相加,结果 3 重新压入栈顶。此时栈内 [3]。7: bipush 10&9: imul: 压入常量 10,弹出 3 和 10 进行乘法,结果 30 压回栈顶。12: ireturn: 将栈顶的 30 弹出,返回给 main 方法,同时销毁当前栈帧,PC 寄存器回到 main 方法的调用点。方法出口(Return Address):当 compute() 执行完毕,它怎么知道回 main 的哪一行?栈帧中存了 “返回地址”,指向 main 指令的第 12 行(即 istore_2)。
- 元空间 (Metaspace): Calculator.class 的结构信息(方法元数据、常量池
#7、#14等)全部存储在元空间中。它不在 JVM 堆里,而是在本地内存。 - 动态链接 (Dynamic Linking):字节码中的 “#14 // Field java/lang/System.out” 就是符号引用。在执行
getstatic时,JVM 会通过动态链接将其转换为真实的内存地址。
最核心的三种 GC
若使用如 Parallel 的传统 GC
如果你手动指定了 -XX:+UseParallelGC,那么 Java 17 的堆结构与 Java 8 基本一致,依然严格划分以下区域:
新生代 (Young Generation):
- 伊甸园区 (Eden):对象诞生的 “产房”。
- 幸存者区 (Survivor Spaces):分为 S0 (From) 和 S1 (To)。
老年代 (Old Generation / Tenured):存放生命周期较长的对象。
1 | public static void main(String[] args) throws InterruptedException { |
1 | $ jvisualvm |
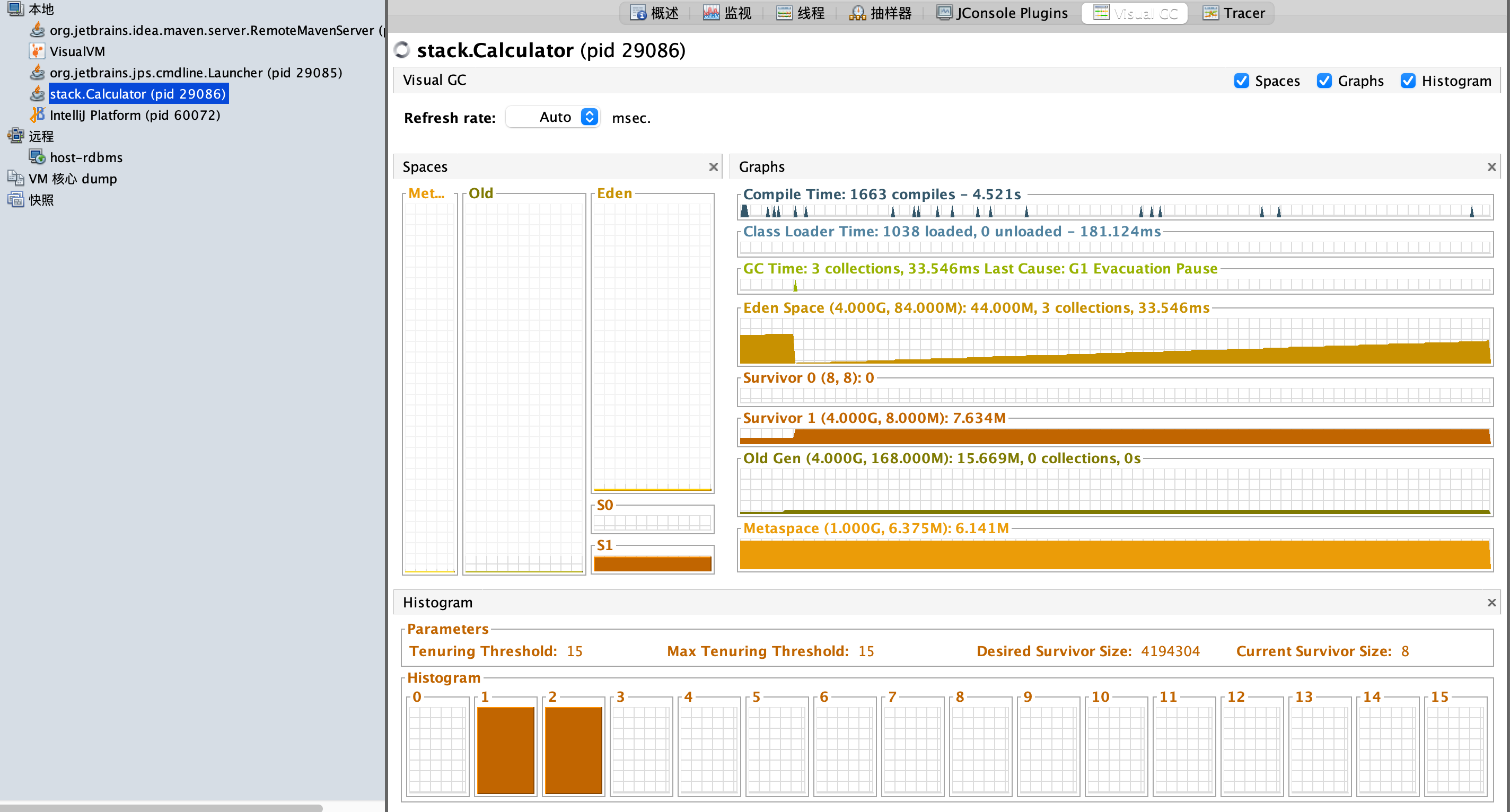
- Eden: 绝大多数对象在此创建。当该区没有足够空间时,JVM 启动一次 Minor GC。此时大部分“短命”对象会被直接回收
- Survivor (S0/S1): 遵循
From与To交换机制。GC 后存活对象在 S0/S1 间来回移动 - 晋升机制: 每经历一次 GC,对象年龄 +1。达到阈值(默认 15)后进入老年代。
- 存储大对象、或经过多次 GC 依然存活的“长寿”对象。
- 当老年代空间不足时,触发 Full GC 回收整个堆,这通常会导致较长时间的 STW(停顿)。
- 在 Java 17 中,G1 极大地减少了 Full GC 的发生频率。
注1:在 JDK 17 中,元空间存储的是类的结构(元数据),它使用本地物理内存。
注2:在传统的垃圾回收模型中(如上图),内存被死板地划分为物理隔离的区域,这导致了‘碎片化’和‘调优困难’。而 Java 17 默认的 G1和旗舰级 ZGC 则打破了这种僵化的边界,实现了更灵活的按需分配。
若使用 17 默认的 G1 GC
在 JDK 17 中,默认的 G1 (Garbage First) GC 彻底打破了物理内存的固定边界。它不再像传统 GC 那样将堆简单地切成两块(年轻代/老年代),而是将整个堆拆解为约 2048 个大小相等的 Region(区域)。
点击下方按钮观察对象在 Region 间的流转
物理结构:从 “大陆” 到 “群岛”:传统 GC (Parallel/CMS),内存像两块巨大的大陆(新生代大陆和老年代大陆)。如果老年代大陆满了,必须进行一次耗时极长的全岛大扫除。G1 GC 内存像数千个微型岛屿 (Regions),每个岛屿的职责(Eden/Survivor/Old)是动态分配的。
核心逻辑:从“清理”到“搬运”:动画中你会发现,G1 在回收时,不是原地清扫,而是将存活对象搬运 (Evacuation) 到全新的岛屿上。这样做的好处是回收完成的同时,内存也自动整理整齐了,完全规避了传统 CMS GC 最头疼的内存碎片问题。
为什么叫 Garbage First?:在最后一步(Mixed GC)中,你可以观察到并不是所有的红色(Old)区域都被清理了。G1 会建立一个 “垃圾收益排行榜”,优先选择那些 “垃圾多、回收快” 的 Region。这种 “欺软怕硬” 的选择性回收,正是它能控制停顿时间在 200ms 以内的秘密。
若使用 17 强推的 ZGC
作为 JDK 17 的“镇馆之宝”——ZGC (The Z Garbage Collector),它的设计哲学则是完全不同的:追求极致的低延迟。如果你开启了 -XX:+UseZGC,那么传统的隔离概念彻底消失了。
- 没有分代:在 Java 17 的 ZGC 中,它是不分代的(注:直到 Java 21 才引入分代 ZGC)。
- 基于 Page 页的动态内存布局:ZGC 将内存分为小型(2MB)、中型(32MB)和大型(动态)页面。
- 不存在 S0/S1/伊甸园:对象直接在 Page 中分配,回收时通过 “重定位” 移动对象,没有新生代晋升老年代繁琐过程。
Java 17 实现了内存管理的 ‘去中心化’。虽然我们熟悉的 Eden 和 Survivor 概念在默认的 G1 引擎中依然作为逻辑标签存在,但物理上它们已经化整为零。而随着 ZGC 的成熟,Java 正在迈向一个 无分代、全动态分配 的新纪元,彻底终结了手动调优新生代比例的痛苦。在 G1 中无论怎么优化,Evacuation(对象搬运)阶段依然需要 STW (Stop The World)。而 ZGC 的核心突破在于:它把最耗时的对象搬运过程,做成了与业务线程并发执行。
停顿时间固定在 1ms 以内,无论堆内存是 8MB 还是 16TB
停顿时间 (Pause Time) 的跨代飞跃:G1 停顿时间与堆内存中存活对象的数量成正比。如果堆很大(比如 128G),STW 可能达到数百毫秒。ZGC 停顿时间只与GC Roots(如局部变量、静态变量)的数量有关,与堆大小无关。这意味着 10MB 的堆和 10TB 的堆,停顿时间都控制在 1ms 以内。
内存布局:Page vs Region:G1 所有的格子 (Region) 大小必须一致。ZGC 采用动态大小的 Page。Small Page (2MB) 存放小对象,Medium Page (32MB) 中型对象。Large Page (N x 2MB) 存放超大对象。这种灵活的分配方式让 ZGC 甚至不需要 “巨型对象区” 这种特殊处理。
核心技术:彩色指针 (Colored Pointers)这是 ZGC 最硬核的地方。传统 GC 如果要判断一个对象是否被移动过,必须去查表或者看对象头。ZGC 直接利用 64 位机器指针中高位未使用的 4 位(Marked0, Marked1, Remapped, Finalizable),只要拿到指针地址,CPU 就能瞬间知道了这个对象现在在不在正确的位置,如果不在,它又在哪。
读屏障 (Load Barriers):比如你在玩一个游戏,可当前服务器正在迁入新机房。传统 GC (STW) 迁入期间,所有玩家必须下线,等服务器搬完再上线。而 ZGC (并发) 搬迁期间你可以继续玩。当你访问服务器 A 时,读屏障发现 A 已经搬到 B 了,它会透明地帮你转向 B,并顺手更新你的快捷方式(自愈)。
所以在实际的使用中:如果你的应用更看重整体吞吐量(例如后台批处理任务),G1 依然是平稳的首选;但如果你的应用是低延迟敏感型(例如即时通信、金融交易、游戏服务端),那么 JDK 17 中的 ZGC 是毫无疑问的王牌选择,它让 Java 程序员彻底告别了对 GC 停顿的恐惧。
完整 JVM 调优方案包含的内容
A. 编译调优 (JIT Tuning)
内容:调整代码从字节码变成机器码的过程。
参数示例:-XX:ReservedCodeCacheSize(控制存放热点代码的空间)。
核心目的:是让核心业务代码(如双十一下单逻辑)跑得像原生 C++ 一样快。
B. 内存空间布局调优 (Non-Heap Tuning)
内容:管理堆以外的内存,如元空间 (Metaspace)、直接内存 (Direct Memory)、线程栈 (Stack)。
参数示例:-XX:MaxMetaspaceSize、-Xss (调整每个线程占用的内存)。
核心目的:防止因为线程过多导致物理内存溢出。
C. 类加载调优
内容:优化类搜索路径、预加载等。
参数示例:-Xshare:on (开启 CDS,加快启动速度)。
D. GC 调优 (狭义)
基本上 80% 的实际场景中,JVM 的性能瓶颈都出现在内存管理上。当一个 Java 应用“变慢”或“卡死”时,排查的第一步通常是查看 GC 日志。GC 调优是见效最快、手段最直接的。 相比于调整复杂的 JIT 参数,改一个 -Xmx 或换一个 GC 带来的性能提升通常是立竿见影的。所以在技术讨论中,人们习惯性地用 “JVM 调优” 代指 “GC 调优”,这虽然不严谨,但符合生产环境的直觉。
针对三种GC的启用和调优方案
怎样启用某种 GC
在 Java 17 中,你只需通过一行 JVM 参数即可切换不同的垃圾回收引擎。
- Parallel GC:开启参数是
-XX:+UseParallelGC,适用于离线数据处理、后台科学计算(追求纯粹的吞吐量)。 - G1 GC:开启参数是
-XX:+UseG1GC(默认已开启),适用于大多数生产环境(JDK 17 默认,平衡延迟与吞吐)。 - ZGC:开启参数是
-XX:+UseZGC,适用于金融交易、低延迟游戏、超大内存(追求极低停顿)。
你可以运行以下命令来确认当前 JVM 实际使用的 GC:
1 | $ java -XX:+PrintCommandLineFlags -version |
每种GC的调优思路
调优不是玄学,它有三个具体的量化指标:
降低 STW 的停顿时间:防止 UI 界面卡顿、接口响应超时或分布式系统中的 “假死” 心跳检测。提高吞吐量 (Throughput):让 CPU 更多地处理业务逻辑,而不是在忙着清扫内存。防止 OOM 和 Full GC:Full GC 是调优失败的标志。 调优的终极目的是让年轻代/老年代在 “微循环” 中解决问题,永远不要触发那种全局性的、长时间的“大扫除”。
G1 GC 调优(最常用)
G1 是 “自适应” 的,调优的首要原则是:尽量少手动干预。
- 设定停顿目标:这是 G1 最重要的参数。-XX:MaxGCPauseMillis=200(默认 200ms)。如果你希望延迟更低,可以设为 100,但要注意这会降低吞吐量。
- 不要手动设年轻代大小:一定要避坑,不要使用 -Xmn。G1 需要动态调整年轻代大小来满足你的 MaxGCPauseMillis 目标。一旦固定了大小,G1 的自适应策略就失效了。
- 调整并发标记触发点:-XX:InitiatingHeapOccupancyPercent=45。如果老年代增长太快,可以调低此值(如 35),让 G1 更早开始回收。
ZGC 调优(极简主义)
ZGC 的设计目标是 “无须调优”,它甚至不需要你设置新生代大小。
- 唯一关键的是堆内存的大小:-Xmx 和 -Xms,ZGC 只需要足够的空间来进行并发搬运。如果堆太小,会导致 “分配速率过快” 而触发严重的阻塞。
- 开启并行线程数:-XX:ConcGCThreads=4。如果 CPU 资源充足且垃圾产生极快,可以适当调高。
Parallel GC 调优
控制最大停顿时间:-XX:MaxGCPauseMillis。
控制吞吐量占比:-XX:GCTimeRatio=99(表示垃圾回收时间不超过 1%)。
高吞吐和高并发调优案例
案例一:淘宝双十一 “历史订单汇总系统”(典型的高吞吐系统)
场景描述:该系统不直接面向用户下单,而是负责在双十一期间,每隔 5 分钟将海量已支付订单进行汇总、加密并推送至仓库系统。
性能痛点:
- 对象生命周期:90% 的订单对象在处理完后即变为垃圾。
- 压力特征:瞬间产生数百万个小对象(订单行),需要极快的分配速率。
- 目标:在 1 小时内处理完 10 亿行订单,不能让 GC 占用过多的 CPU 时间。
对于典型的高吞吐的系统,优先选择 Parallel GC,其核心设计哲学就是:不惜代价缩短总运行时间,让 CPU 满负荷处理业务逻辑,哪怕单次 GC 停顿稍长。在这种极端的场景下,Parallel GC 调优的核心目标只有两个:
- 延迟 Full GC 的到来:老年代满了之后的 Full GC 是灾难。通过增大年轻代和 Survivor,我们希望在 5 分钟的批处理周期内,甚至一次 Full GC 都不发生。
- 吞吐量最大化:让 CPU 尽可能多地执行 orderService.process(),而不是在 GC task 上打转。
具体来说针对此类 “高吞吐” 场景,我们需要从 空间换时间 和 并行压制 两个维度入手。
- 基础资源对齐(防止内存抖动):在压力巨大的双十一,JVM 动态扩容(从 -Xms 扩到 -Xmx)会导致严重的系统抖动和性能损耗。参数配置成 -Xms8g -Xmx8g,目的是让应用 “起步即峰值”,启动时就向操作系统申请全部内存,避免运行期间因申请内存导致的 STW。
- 年轻代比例调优(减少 Minor GC 频率):Parallel GC 的默认年轻代/老年代比例是 1:2。在订单海量生成的场景下,年轻代过小会导致 Minor GC 过于频繁。参数配置成 -XX:NewRatio=1 或直接指定 -Xmn4g,目的是扩大 Eden 区。让更多的订单对象在年轻代就被消化掉,减少进入老年代的对象数量,从而极大地推迟 Full GC 的到来。
- 幸存者区与晋升控制(防止过早晋升):
- 参数配置 -XX:SurvivorRatio=6 (默认 8),目的是调大 Survivor 区。双十一订单处理链路较长,对象存活时间略长。增大 Survivor 空间能让对象在年轻代多待一会儿,避免它们“因空间不足”提前挤进老年代引发 Full GC。
- 参数配置:-XX:MaxTenuringThreshold=15,目的是尽量让对象在年轻代“老死”,不要去老年代占位置。
- 吞吐量目标设定(核心指令):Parallel GC 是靠目标驱动的。参数配置为 -XX:GCTimeRatio=99,目的是告诉 JVM,我希望 99% 的时间在跑业务,只有 1% 的时间在做 GC。如果达不到,JVM 会自动调整堆大小。
所以综上所述,假如我们的服务器是 16 核 32G 内存,那么实操建议就是:
1 | $ java -server \ |
案例二:淘宝双十一核心下单系统(典型的高并发场景)
流量特征:瞬时秒杀,QPS(每秒请求数)极高。
对象特征:
- 短命对象多:每个下单请求产生的大量 DTO、VO、局部变量,在请求结束(毫秒级)后即成垃圾。
- 缓存对象多:为了加速,本地缓存了大量的热点商品信息(长寿对象)。
核心目标:极致低延迟。99% 的请求必须在 100ms 内返回,严禁出现长达 1s 的 STW。
面对双十一 “下单系统” 这种直接对 C 端用户提供服务的场景,调优逻辑与之前的批处理系统(Parallel GC)完全相反。C 端系统的核心痛点是响应时间(RT, Response Time)。用户点击 “立即下单” 后,如果 JVM 此时发生一次 500ms 的 GC 停顿,用户就会看到转圈圈,甚至因超时导致订单失败。因此 G1 GC 或 ZGC 是唯一的工业级选择。
G1 调优方案
G1 的设计的核心目标是 “可预测的停顿”,在 Java 17 中,它处理这种场景已经非常成熟。
- 停顿时间驱动(核心配置):不要尝试去手动算 Eden 应该多大,直接告诉 G1 你的期望。设置参数 -XX:MaxGCPauseMillis=100,目的是强制 G1 每次回收控制在 100ms 以内。G1 会据此自动调整年轻代 Region 的数量,确保 “少量多次” 地回收。
- 内存布局(空间换响应):
- 设置参数 -Xms16g -Xmx16g,下单系统通常有 10GB+ 的堆。固定大小可避免双十一期间 JVM 为了申请内存向操作系统发起系统调用。
- 设置参数 -XX:G1HeapRegionSize=16M (或 32M),下单系统会有大对象(如热点商品详情的 JSON 树)。增大 Region 大小可以减少 Humongous Region(巨型区)的碎片化,防止频繁触发并发标记。
- 并发标记调优(预防防老年代溢出):这种典型的高并发系统的老年代通常存满了热点缓存。设置参数 -XX:InitiatingHeapOccupancyPercent=35(默认 45) ,当老年代占用达到 35% 就开始并发标记。双十一流量极快,如果按默认的 45% 才开始,可能还没标记完老年代就爆了,导致 Full GC。
- 线程优化(压榨多核):设置参数 -XX:ParallelGCThreads=16 (假设 16 核)、-XX:ConcGCThreads=4,让 4 个线程在后台不停地标记垃圾,16 个线程在 STW 时全速搬运。
所以综上所述,针对这个 C 端高并发系统,完整的启动指令应该是:
1 | $ java -server \ |
我们的核心目的是消灭 “Stop-The-World” 的长尾效应。对应在 C 端下单系统中,调优的核心目的就是“化整为零”,为了 100ms 的响应,我们宁愿每秒 GC 两次,也不愿 5 秒 GC 一次但停顿 500ms,并且通过 InitiatingHeapOccupancyPercent 提前收割,防止老年代在高峰期 “猝死”。
ZGC 调优方案
如果下单系统对停顿的要求是 10ms 以内,那么 Java 17 真正的杀手锏是 ZGC。ZGC 方案简述:
- 只需一个参数:-XX:+UseZGC -Xmx16g。
- 原理:它几乎所有的回收过程都是并发的,停顿时间与堆大小无关。在双十一这种超大堆场景下,ZGC 能让你的 P99 响应延迟几乎是一条直线。
需要注意的是虽然 ZGC 很香,但也需要注意分配速率竞争的问题。因为在 GC 线程回收内存的同时,下单请求依然在疯狂地 new 对象。G1/Parallel 的逻辑是如果内存不够了,它们会直接 STW(停顿),全速清理出空间再继续。而 ZGC 不会停顿,如果业务产生垃圾的速度快于GC 回收垃圾的速度,内存就会耗尽。
具体在双十一秒杀开启的一瞬间,QPS 从 1k 飙升到 100k,每秒产生 2GB 的临时对象。如果 ZGC 回收一个 Page 需要 0.5 秒,而这 0.5 秒内业务已经申请了 3GB 空间,就会发生 Allocation Stall(分配停滞)。此时,业务线程会被迫挂起,等待 GC 释放空间,RT(响应时间)会从 1ms 直接飙升到数百毫秒甚至秒级,导致系统雪崩。
另外,由于 ZGC 引入了大量读屏障(Load Barriers),每次对象访问都需要额外的判断。相比 G1,ZGC 通常会损失 5%~15% 的吞吐量。
所以对于 ZGC 这种策略,最优的补充做法是 :
- 给 ZGC 预留极其充足的 “呼吸空间”:如果 G1 用 16G 够了,ZGC 建议给到 24G 或 32G。用空间换取缓冲时间,防止分配速率超过回收速率。
- 增加并行回收线程:使用 -XX:ConcGCThreads 适当调高并发线程数(例如设为核心数的 1/2,而不是默认的 1/4)。虽然会抢占业务 CPU,但能加快回收速度。
- 监控 Allocation Stall:查看日志中是否有 Allocation Stall 关键字,一旦出现,说明堆设小了或者并发线程数不够。

使用日志进行调优
打印 -Xlog 日志
在 JDK 17 中,单靠改参数是不够的,你需要看到“证据”。我们在此还是以 Calculator 这个小案例来说明:
1 | // 我们将 compute() 放入一个巨大的循环中,并创建一些临时对象来触发 GC: |
1 | # -Xlog:gc*: 记录所有以 gc 开头的日志信息。 |
开启 NMT 内存追踪
要在 Java 17 中使用 NMT (Native Memory Tracking),需要分两步走:先在启动时打上 “追踪标记”,然后在运行时发送 “抓取指令”。这就像是给 JVM 安装了一个实时监控摄像头,让你看清除了 “堆内存” 之外,非堆、栈、代码缓存和元空间到底吞噬了多少物理内存。
第一步:启动 JVM 时开启追踪
NMT 不能动态开启,必须在 Java 程序启动参数中加入 -XX:NativeMemoryTracking=detail。
1 | $ java -XX:NativeMemoryTracking=detail -Xms128m -Xmx128m stack.Calculator |
注意 :开启 detail 模式会有约 5%~10% 的性能损耗,生产环境建议通常只在排查内存泄漏时开启。
第二步:使用 jcmd 查看内存快照
1 | # 在程序运行期间(不要关闭之前的终端),新开一个终端窗口进行 “抓取”。 |
第三步:深度解读 NMT 报告
执行完命令后,你会得到一张极其详尽的表。重点关注以下几个 “吃内存” 大户:
- Java Heap (堆):Java Heap (reserved=131072KB, committed=131072KB)
- 这是我们设置的 -Xmx128m。
- committed 表示 JVM 已经实实在在向操作系统要到的物理内存。
- Metaspace (元空间):Class (reserved=1056813KB, committed=1024KB)
- reserved 表示预留了 1GB(这是 Java 17 的默认虚拟地址空间,不用担心,不占物理内存)。
- committed: 实际占用的物理内存。如果这个值持续增长,说明你可能在动态生成大量的类。
- Thread (线程栈):Thread (reserved=10240KB, committed=10240KB)
- 每个线程默认占用 1MB 栈空间。如果你开了 1000 个线程,这里就会吃掉 1GB 内存。
- Code (代码缓存):Code (reserved=250000KB, committed=2500KB)
- 这就是之前提到的 ReservedCodeCacheSize。JIT 编译后的机器码全躺在这里。
第四步:追踪内存增长(Baseline)
程序运行稳定后,执行:
1 | $ jcmd 12345 VM.native_memory baseline |
等待一段时间(例如跑了 50 万次运算后),对比执行:
1 | $ jcmd 12345 VM.native_memory summary.diff |
你可能会看到结果中出现了类似 +20KB 的符号。这能让你一眼揪出到底是哪个区域在 “偷偷变胖”。