JUC常用类之任务和线程池相关
相关类的概述
在早期的 Java 并发编程中,我们习惯于直接使用 Thread 和 synchronized。但在现代高并发、高可用的互联网环境下,这种 “小作坊” 式的并发处理逻辑已无法应对。JUC 执行框架的出现,本质上是将任务的提交与执行的机制彻底解耦。
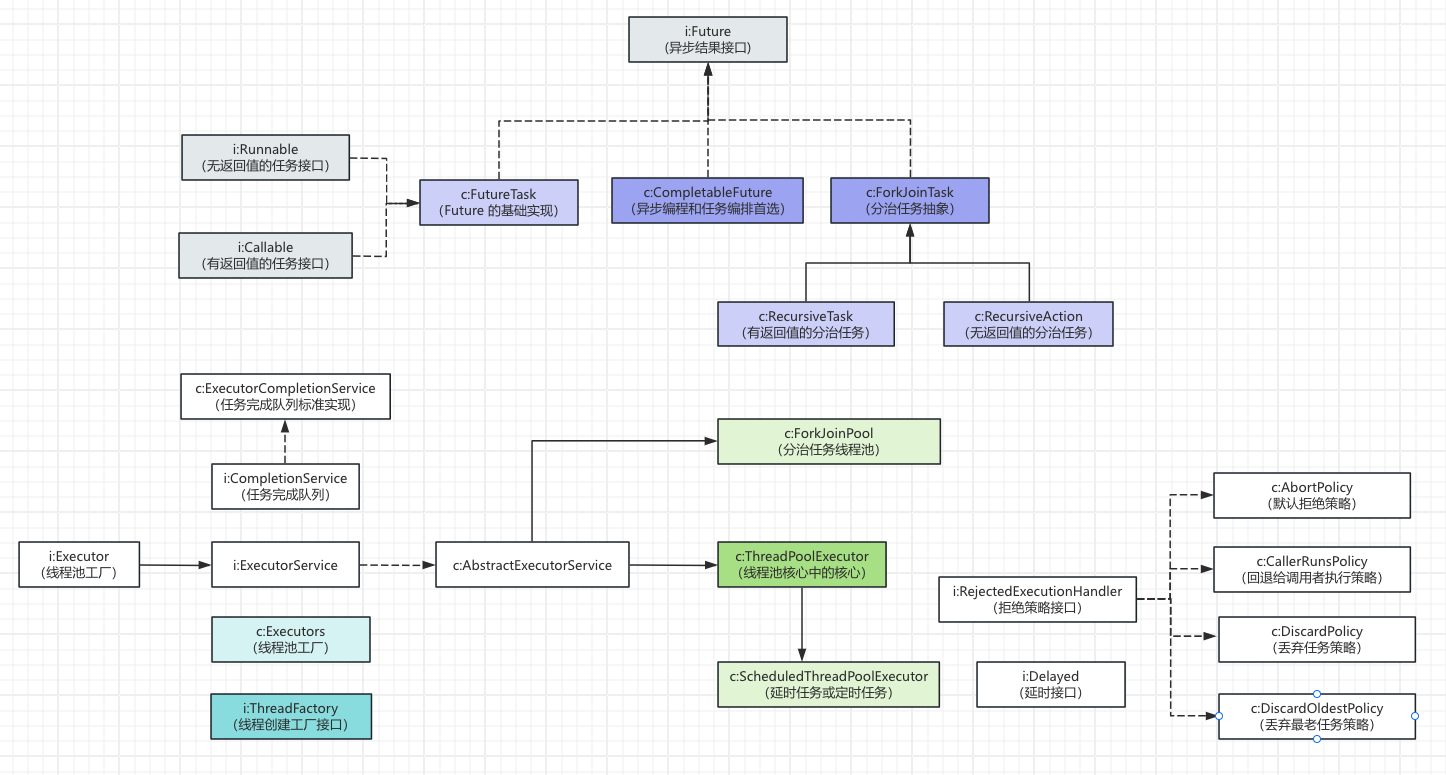
任务抽象:定义 “做什么”
JUC 中的核心类(如 Runnable、Callable、FutureTask)不仅仅是简单的接口封装,它们定义了异步计算的契约:
标准任务:通过 Callable 解决了 Runnable 无法返回结果、无法抛出异常的痛点。
Runnable:最基础任务接口,run 方法无返回值且不能抛出检查异常,属 “发后即忘”(Fire-and-forget)模式。Callable:JUC 引入的增强版,call 方法有返回值并允许抛出异常。它是获取异步计算结果的基础。
状态追踪任务:FutureTask 和 CompletableFuture 充当了任务的 “收据”,让我们可以在未来的某个时刻,非阻塞地获取执行结果或编排后续逻辑。
FutureTask:它既实现了 Runnable 又包装了 Future,既可以包装一个 Callable 或 Runnable,交给线程执行,同时又能通过自身获取执行结果。它是线程池异步执行任务的标准容器。CompletableFuture:Java 8 引入的一个强大的异步编程工具类,它实现了 Future 和 CompletionStage接口,核心解决了传统Future无法异步回调、不支持任务组合编排等痛点,提供了链式调用、异步回调、任务编排等能力,是Java中处理异步任务和并行计算的核心工具。
分治任务:ForkJoinTask 极限压榨多核 CPU 的每一份性能,专门用于 ForkJoinPool 的任务抽象,支持 fork(拆分子任务)和 join(合并子任务)。它的底层采用 “工作窃取” 和 “双端队列” 的方式,空闲线程从其他线程的任务队列尾部“窃取”任务执行,每个工作线程维护一个双端队列,正常任务从尾部入队/出队,窃取任务从头部获取,减少竞争。
-
RecursiveTask:定义有返回值的递归任务。适用于需要合并子任务结果的场景(如求和、查找最大值等)。 -
RecursiveAction:定义无返回值递归任务。适用于修改共享数据或执行副作用操作(如打印、数组修改等)。
-
执行引擎:定义 “怎么做”
在实际开发中,线程池(ThreadPoolExecutor 系列)扮演着资源守护者的角色:
- 降低开销:通过池化技术重复利用已创建的线程,规避了频繁创建、销毁线程带来的数毫秒级延迟(这在每秒万级并发的系统中是致命的)。
- 控制并发上限:作为系统的 “护城河”,它能防止瞬时高流量冲垮后端资源。通过合理的队列(BlockingQueue)和拒绝策略,确保系统在超负荷时能 “优雅降级” 而非崩溃。
- 提升响应速度:配合 ExecutorCompletionService 或 CompletableFuture,可以将串行的业务逻辑并行化。
在设计这套体系时,Java 大师 Doug Lea 遵循了 “接口定义行为、抽象类提取共性、实现类追求性能” 的设计哲学。这对使用者非常友好,你只需要面向 ExecutorService 编程,不管后端是哪种池,代码都能跑。如果你要写一个自己的分布式线程池,你也只需继承 AbstractExecutorService 这个模板类,剩下的包装逻辑大师也都帮你写好了。
Executor:顶层接口,只负责 “运行”。只有一个方法 execute(Runnable)。我认为这个接口的设计初衷就是为了彻底解耦。提交者只需知道这个任务会被执行,而不需要关心它是被谁具体怎么执行。ExecutorService:功能扩展接口,只负责 “管理”。增加了管控生命周期相关方法。大概是 Executor 太简单了,没法关闭,没法查看任务执行结果。所以这一层增加了 shutdown()、submit()(返回 Future)等管理方法。AbstractExecutorService:模板抽象类,减少重复代码,它只关心 “如何跑出结果”。它实现了 submit 等方法,将任务包装成 FutureTask,然后调用底层的 execute。ThreadPoolExecutor:最核心的线程池标准实现,设计的初衷就是为了解决资源爆炸问题。通过 7 大参数(核心线程、最大线程、等待队列、拒绝策略等)精准控制硬件资源的利用率。ScheduledThreadPoolExecutor(定时任务线程池):继承自 ThreadPoolExecutor,专门处理延时任务或周期性任务。内部使用 DelayedWorkQueue(小顶堆结构),确保任务能按预定时间准时触发,替代了传统简陋的 Timer。ForkJoinPool(分治任务线程池):直接继承 AbstractExecutorService,因为它不需要普通线程池那种复杂的拒绝策略和标准的队列逻辑,它有自己独特的 Work-Stealing 队列算法。当某个线程空闲时,会从其他繁忙线程的任务队列末尾 “窃取” 任务执行,极大提高了多核 CPU 在处理大规模递归任务(如 Stream 并行流)时的效率。
注意到没有?ForkJoinPool 并没有继承 ThreadPoolExecutor。ThreadPoolExecutor 是所有线程共用一个阻塞队列。而 ForkJoinPool 是每个线程都有自己的双端队列。如果强行继承 ThreadPoolExecutor,会带入大量无用的加锁逻辑(因为普通池的队列需要全局锁),这会严重拖慢 ForkJoin 的窃取效率。
结果编排:定义 “完事咋办”
CompletableFuture:异步编排神器,由 Java 8 引入,它彻底改变了 Java 异步编程的体验。它支持链式调用(thenApply、thenCombine 等)、异常处理以及多个异步任务的组合(AllOf/AnyOf),是响应式编程的重要体现。ExecutorCompletionService:它是一个结果收集器,内部维护了一个阻塞队列。当提交一批任务时,它能让我们按 “谁先做完谁先出队” 的顺序来获取结果,而不需要按提交顺序死等。
辅助类:定义 “生产标准”
Executors:提供了快速创建线程池的方法(如 newFixedThreadPool)。需要注意的是 ,这个类虽然方便,但在生产环境下应该弃用 Executors 的快捷方法,因为它默认的无界队列可能会导致 OOM,还是建议手动配置 ThreadPoolExecutor 7大参数以防止 OOM。ThreadFactory:一个简单线程定制器接口,用于定义如何创建新线程。通过自定义工厂,你可以为线程池中的线程起个好听的名字、设置优先级或设为守护线程,这对于排查 jstack 日志至关重要。
在生产环境中,JUC 类的运用应遵循以下规则:
- 强制手动配置:弃用 Executors 的快捷方法,通过 ThreadPoolExecutor 手动指定 7 大参数以防 OOM。
- 命名规范:利用 ThreadFactory 为每个业务池的线程打上唯一标签,以进行异常日志追踪。
- 异步编排:由简单 Future 转向 CompletableFuture,利用其回调机制彻底消除 “阻塞等待结果” 的情况。
任务类相关的案例
最基础的抽象任务
Runnable:最纯粹的 “发后即忘”,异常只能在内部处理
1 | // Runnable 案例:仅执行动作,没有返回值 |
Callable:带反馈的任务定义(配合Future们或线程池们使用),异常可向上抛出
1 | Callable<Integer> calculateTask = () -> { |
Future:任务执行的 “提货单”,异常可继续向上抛出
1 | ExecutorService executor = Executors.newFixedThreadPool(1); |
FutureTask:全能的 “包装者”,异常可继续向上抛出
1 | // FutureTask 案例:手动包装 Callable |
更强大的编排任务
CompletableFuture 是 Java 8 引入的异步编程里程碑,彻底解决了传统 Future 必须通过 get 阻塞获取结果或不停轮询 isDone 的尴尬。它的 API 非常丰富(约有 50 多个方法),根据 “任务流转的阶段” 和 “触发机制” 可以将其划分为以下 7 大类。
任务创建 (Initiating) - 这类方法用于开启一个异步流程。
supplyAsync(Supplier<U> s)- 有返回值,在后台异步执行,返回结果。runAsync(Runnable r)- 无返回值,仅异步执行动作。completedFuture(U value)- 创建一个已完成状态的 Future,常用于 Mock 或立即返回。
结果转换与消费 (Processing) - 当上一个阶段完成后,如何处理它的结果。
thenApply(Function fn)- 转换。拿到结果 A,处理后返回结果 B。类似 Stream 的 map。thenAccept(Consumer action)- 消费。拿到结果 A,处理但不返回任何东西。thenRun(Runnable action)- 单纯触发。不关心上一步结果,只要上一步完了我就执行。thenCompose(Function fn)- 扁平化嵌套。返回一个新的 CF。类似 Stream 的 flatMap。
- 多任务组合 (Combining) - 处理两个 Future 之间的逻辑关系。
AND 关系- thenCombine - 两个都完,合并结果返回。
- thenAcceptBoth - 两个都完,消费结果。
- runAfterBoth - 两个都完,执行动作。
OR 关系- applyToEither - 谁快用谁的结果进行转换。
- acceptEither - 谁快用谁的结果进行消费。
- runAfterEither - 只要有一个完,就执行动作。
- 多任务并行 (Orchestrating) - 处理任意数量(N个)Future 的协作。
allOf(CF... cfs):全家桶模式。所有任务都完成,返回 CompletableFuture。anyOf(CF... cfs):赛跑模式。只要有一个任务完成,返回最快那个人的结果 CompletableFuture\<Object>。
- 异常处理 (Exception Handling) - 异步链路中的 “救生圈”。
exceptionally(Function fn):只在发生异常时触发,返回一个兜底值。handle(BiFunction fn):无论正常还是异常都会触发,可以同时处理结果和异常。whenComplete(BiConsumer cb):类似 finally,不改变结果,只做观察或记录。
- 结果获取 (Fetching) - 从异步世界回到同步世界。
get():阻塞获取,抛出检查异常(InterruptedException, ExecutionException)。join():阻塞获取,抛出运行时异常(更常用)。getNow(T defaultValue):如果没完就拿默认值,不阻塞。complete(T value):手动完成该 Future。
- 交互与超时 (Java 9+ 增强)
orTimeout(long, TimeUnit):规定时间内没完就抛出异常。completeOnTimeout(T, long, TimeUnit):规定时间内没完就给个默认值。copy():返回一个副本,防止被外部手动 complete 破坏。
下面我们通过一些小案例,来具体看看这个类的具体用法 。
异步任务链:thenApply (流水线模式)
场景:模拟电商下单流程:1.查询价格 -> 2.计算折扣 -> 3.生成账单。每一跳都依赖前一跳的结果。
1 | CompletableFuture<String> orderFuture = CompletableFuture.supplyAsync(() -> { |
异步任务的 “套娃” 摊平:thenCompose
场景:你需要先异步获取 “用户ID”,拿到 ID 后再异步获取 “该用户的订单”。
如果用 thenApply,返回值会变成 CompletableFuture<CompletableFuture<Order>> 产生嵌套,而 thenCompose 会将结果 “摊平”,返回 CompletableFuture<Order>。
1 | CompletableFuture<String> userIdFuture = CompletableFuture.supplyAsync(() -> "User_123"); |
多任务组合:thenCombine (结果聚合模式)
场景:首页展示需要同时获取 “用户信息” 和 “广告推荐”,两者互不依赖,但最终需要合并成一个对象发给前端。
注意:如果参与合并的其中一个任务抛出异常,那么最终合并后的 Future 也会直接进入异常处理流程。
1 | CompletableFuture<String> userFuture = CompletableFuture.supplyAsync(() -> { |
多任务并行:allOf (分布式查询模式)
场景:在后台需要同时扫描 10 篇文章的 SEO 状态。你希望等所有扫描都完成后,发一个 “扫描完成” 的通知。
注意:如果其中一个任务失败,allOf 返回的 Void Future 也会被标记为失败。但由于它不直接承载结果,通常需要遍历原始列表来检查具体是哪个任务出错了。
1 | List<CompletableFuture<String>> futures = Stream.of("Post1", "Post2", "Post3") |
容错处理:exceptionally (熔断保护模式)
场景:调用远程 API 时,如果接口超时或报错,不能让整个页面崩溃,而是给出一个默认的 “兜底值”。
1 | CompletableFuture<String> safetyFuture = CompletableFuture.supplyAsync(() -> { |
全能的结果/异常处理器:handle
场景:无论前面的任务是成功拿到了数据,还是中途崩了(抛异常),你都想统一处理。你可以通过 handle 能同时拿到 result 和 exception 两个参数,并且可以改变返回值。
1 | CompletableFuture<Integer> handleFuture = CompletableFuture.supplyAsync(() -> { |
手动给任务画句号:complete
场景:你启动了一个异步任务,但如果超过 2 秒没回消息,你想手动设置一个默认值让流程继续走下去。
注意:complete 是 “写入” 操作,它在说 “别等了,我现在就把结果定死成这个值”。而 getNow 只是 “读取” 操作,对任务完全没有影响,它只是询问 “现在有结果了吗?没有我就拿个默认值走人”。
用法:① 如果你觉得自己有更快的路子,这任务可以提前收工,那就用 complete;② 如果你等不及了,现在就要个结果,那就用 getNow。
1 | CompletableFuture<String> manualFuture = new CompletableFuture<>(); |
ThreadPoolExecutor
七大核心参数形象说明
店内正式工:咖啡馆最基础的员工。即便没有客人(任务),他们也会在店里待着,不会被开除。当新订单进来时,只要正式工还没满载,老板就会优先雇佣正式工。
排队等候区:如果正式工都在忙,新来的客人就得去沙发区坐着排队。只有沙发区坐满了,老板才会考虑找临时工帮忙。
最大承载量:正式工忙不过来且沙发区也坐满了,老板紧急招募的“临时工”。正式工 + 临时工的总数不能超过这个天花板。
辞退前的观察期:当客流量减少,临时工闲着的时间超过这个值,就会被“结账辞退”。但正式工(核心线程)不受这个限制。
人事登记部:新员工入职时领工牌。你可以给他们起名字、设优先级、标记是否为守护线程等。
拒收方案:人手全满了,沙发也没座了,新来的客人怎么办?是直接关门拒客(Abort),还是让客人自己回家煮咖啡(CallerRuns)?
这种设计模型实现了 “削峰填谷”。
- 低负载:只有正式工在,资源消耗小。
- 突发流量:通过队列缓冲,不至于瞬间压垮系统。
- 极高负载:通过临时工提升处理速度,如果还是扛不住,通过拒绝策略保护系统不至于 OOM 崩溃。
源码深度拆解
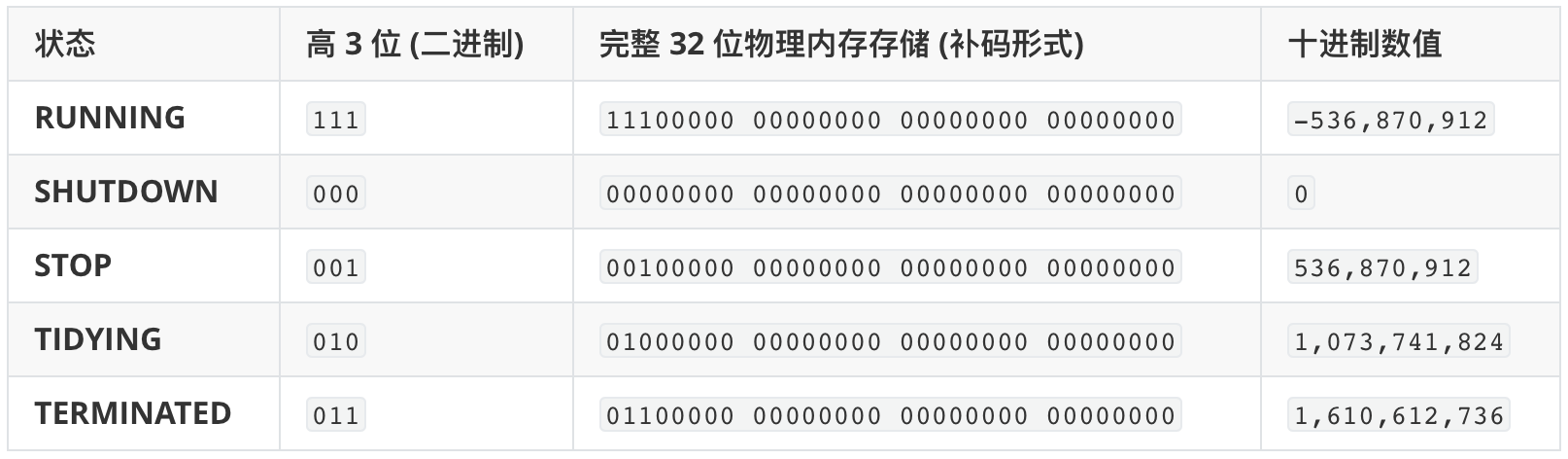
1. 核心控制变量:ctl 的奥秘
在源码的最开头,你会看到这个精妙的设计:
1 | // 这是 Doug Lea 的神来之笔。他利用一个 32 位的 int 表达了两个含义: |
2. 核心入口:execute 方法
这是任务进入线程池的第一站。源码逻辑清晰地体现了我们之前提到的上图中的三段式流程:
1 | public void execute(Runnable command) { |
3. 工作线程的本质:Worker 内部类
线程池里的线程并不是原生的 Thread,而是被包装成了 Worker。
- 继承了 AQS:Worker 本身继承了 AbstractQueuedSynchronizer,实现了一个不可重入的锁。这保证了在执行任务时,线程不会被 interruptIdleWorkers(中断空闲线程的操作)所中断。
- Runnable 包装:每个 Worker 都是一个任务执行单元,它的 run 方法会调用 runWorker(this)。
4. 线程复用的灵魂:runWorker 与 getTask
为什么线程跑完一个任务不会死掉?答案就在 runWorker 的 while 循环里。
1 | final void runWorker(Worker w) { |
getTask():控制线程生死的闸门,它的内部会根据参数决定如何获取队列任务:
- 核心线程:通常调用 workQueue.take(),如果队列没任务,它会一直阻塞直到有新包裹进来(对应 keepAliveTime 无效的情况)。
- 非核心线程:调用 workQueue.poll(keepAliveTime, unit),如果超过存活时间还没拿到任务,就返回 null,导致 runWorker 退出循环,线程销毁。
源码中还定义了线程池的 5 种状态,理解它们的流转对故障排查至关重要:
- RUNNING:接受新任务,处理队列任务。
- SHUTDOW:不接新任务,但处理队列任务。
- STOP:不接新任务,不处理队列任务,中断正在跑的任务。
- TIDYING:所有任务已终止,线程数为 0,准备执行 terminated()。
- TERMINATED:terminated() 执行完毕。
1 | /** |
应用案例
博客内容分发执行器:
1 | import java.util.concurrent.*; |
演示实时修改正在运行的线程池参数。
1 | import org.springframework.web.bind.annotation.*; |
当调用 setCorePoolSize(newSize) 时,线程池内部会发生以下动作:
- 如果新值小于旧值:线程池不会立刻杀掉多余线程,而是等它们完成当前任务后,在下一次获取任务getTask() 时,因为数量超过了新核心数,它们会被回收。
- 如果新值大于旧值:线程池会立即计算差值,并根据需要启动新的工作线程 Worker 来处理队列中堆积的任务。
需要注意的是:
- 线程池的队列容量无法动态修改:因为原生的 LinkedBlockingQueue 的 capacity 字段是 final 的,无法通过 API 直接修改。如果需要动态修改队列大小,可以自定义一个类继承 LinkedBlockingQueue,并去掉 capacity 的 final 修饰符,提供 Setter 方法。
- 实际项目中,通常不会通过 Controller 手动改,而是接入 Apollo 或 Nacos。监听配置中心的 Key 变化 -> 触发回调函数 -> 执行 EXECUTOR.setCorePoolSize()。
- 不要盲目调优。可以配合 Prometheus + Grafana,将 getStatus() 中的数据打入时序数据库,观察线程池的利用率曲线。如果 activeCount 长期接近 maximumPoolSize,才是该加人的时候。
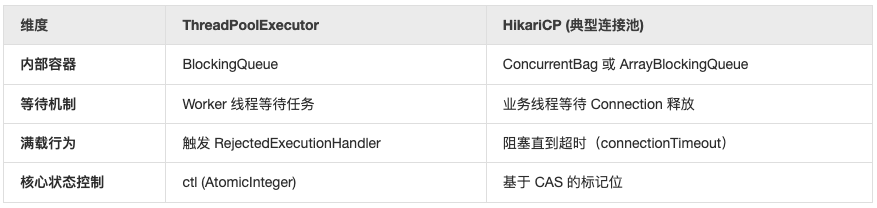
线程池和连接池的对比
线程池和常用的连接池都不约而同地采用了 池化思想,它们的核心在于 “复用那些创建和销毁成本极高的对象”。
- 线程的创建涉及内核态切换和栈空间分配(约 1MB)。
- TCP 连接的创建涉及三次握手、身份验证以及数据库端的进程/线程开销。
它们都是通过 “空间换时间”,在内存中维护一组长寿对象,从而降低系统的响应延迟。它们的不同点在于,虽然都叫 “池”,但管理的资源对象、阻塞机制以及解决的问题有显著区别。
- 核心差异在于管理工人 vs 管理工具:线程池(Thread Pool)管理的是执行力(CPU 资源)。线程像是一个 “工人”,它通过主动去拿任务(Runnable)来干活。连接池 (Connection Pool) 管理的是通道(I/O 资源),它本身并不具备执行任务的能力,它只是一个存放昂贵资源的容器。连接(如 JDBC、Redis 连接)更像是一个 “扳手”。工人(线程)需要拧螺丝时,去池里借一把扳手,用完后再还回去。
- 交互逻辑的倒置:在 Java 源码层面,两者的交互逻辑是相反的:线程池是把任务 execute(task) 丢进去,线程池内部的 Worker 线程通过 workQueue.take() 阻塞式地抢任务。连接池是你的业务线程主动调用 dataSource.getConnection()。如果池子里没连接了,业务线程会调用 condition.await() 挂起,直到有其他线程还回连接。
ScheduledThreadPoolExecutor
在 JUC 体系中,ScheduledThreadPoolExecutor 是专门用来处理延时任务和周期性任务的 “定时炸弹”。相比于传统的 Timer,它解决了单线程阻塞和异常崩溃导致后续任务失效的问题,是 “系统自动化运维” 的核心组件。
工作原理
ScheduledThreadPoolExecutor 核心依靠的是 DelayedWorkQueue(延迟阻塞队列) 和 LockSupport(线程挂起/唤醒)机制,其工作依靠三个核心组件:
A. 任务的封装:ScheduledFutureTask
当你提交一个定时任务时,它会被包装成一个 ScheduledFutureTask。这个对象除了包含你的 Runnable 任务外,还多了两个关键属性:
- time:任务下一次应该执行的纳秒级绝对时间。
- period:重复执行的间隔时间。
B. 核心容器:DelayedWorkQueue
这是它的 “秘密武器”。这是一个基于小顶堆(Min-Heap)实现的优先级队列。小顶堆的插入和删除复杂度仅为 O(log n),处理成千上万个定时任务也非常高效。
- 堆顶永远是执行时间最靠前的任务(即最快要到期的任务)。
- 这种结构使得线程只需要关注“最近的一个任务”,而不需要扫描整个任务列表。
C. 线程的获取逻辑
工作线程(Worker)确实在一个循环中运行,但它在等待任务时是被挂起(Park)的,并不消耗 CPU。
具体的“定时”逻辑如下:
- 线程从 DelayedWorkQueue 中取出堆顶任务。
- 计算:delay = 任务执行时间 - 当前时间。
- 如果 delay <= 0:说明任务到期,立刻执行。
- 如果 delay > 0:说明还没到点,线程调用 Condition.awaitNanos(delay)。此时,底层调用的是 LockSupport.parkNanos(),结果线程进入等待状态,释放 CPU 资源,由操作系统内核负责在 delay 时间后唤醒该线程。
D. DelayedWorkQueue 的 Leader-Follower 模式
为了防止大量线程在同一时间被唤醒去争抢同一个堆顶任务(惊群效应),DelayedWorkQueue 使用了 Leader-Follower 模式,这极大地减少了不必要的定时器唤醒和线程上下文切换开销:
- Leader 线程:第一个到达队列的线程成为 Leader,它被允许进行限时等待(awaitNanos)。它就像是 “守夜人”,到点之后执行自己的任务,并唤醒堆顶的 Follower 让其成为下一个 Leader。
- Follower 线程:其他后来的线程发现已经有 Leader 了,它们就不再关注具体时间,而是进入无限期等待(await),它们不需要定闹钟,只需要等 Leader 的信号。
在没有 Leader 模式时,10 个线程会被同时唤醒。而在 Leader 模式下,同一时刻只有一个线程在进行 “定时唤醒”。这避免了大量线程瞬间状态切换带来的 CPU 负荷。每个线程如果调用 awaitNanos(delay) 实际上都会在操作系统底层注册一个定时器。如果线程池很大,成百上千个线程同时注册 10 秒后的定时器,对内核来说是一种压力。而在 Leader 模式下,只有一个线程在维护那个延迟闹钟。由于只有一个 Leader 会在任务到期时醒来,因为其他线程还没被唤醒,它取走堆顶任务时几乎没有竞争。当它取完任务发出信号后,下一个 Leader 才产生。这把原本“并行的哄抢”变成了“有节奏的交接”。
1 | public E take() throws InterruptedException { |
Leader-Follower 模式本质上是一种 “局部负载均衡”。它通过极小的内存开销(一个 Thread 引用),换取了在高并发下极其稳定的 CPU 表现。
常见用法
1. 资源清理与心跳检测 (Heartbeat)
这是最常见的用法。模拟分布式系统中,每隔固定时间向注册中心发送一次心跳,或者定期清理本地缓存。
关键方法:scheduleAtFixedRate(固定速率),适用于资源竞争型任务(如防止多个备份任务重叠执行)。
1 | ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(1); |
[注1] scheduleAtFixedRate 的设计初衷是维持总体的执行频率。如果任务超时,它会遵循以下三个原则:
绝不并发:同一个 ScheduledThreadPoolExecutor 中的同一个任务,不会在多个线程中同时跑。即使上一个没完,下一个也不会开始。
立即触发:一旦上一个任务完成,如果此时已经超过了预定的下一个触发点,下一个任务会立刻开始执行。
不丢失任务:它不会因为超时就跳过某个批次,而是会尝试把欠下的次数“补”回来,直到追上预定的时间轴。
[注2] 如果你的任务执行时间长期大于频率时间,会产生以下后果:
任务堆积:虽然不会并发执行,但 DelayedWorkQueue 里的任务会一直处于 “待执行” 状态。
线程被占死:该线程池中的某个线程会被这个任务永久占用,不停地在“干活-结束-立刻干活”之间循环。
失去定时意义:原本的“定时”变成了“连续执行”,失去了波峰波谷的缓冲。
2. 具有“间歇期”的循环任务 (Fixed Delay)
如果任务执行本身很耗时,且你希望前一个任务结束后,再等待固定的时间才开始下一个,则必须使用 scheduleWithFixedDelay。
关键方法:scheduleWithFixedDelay(固定延迟),适用于资源竞争型任务(如防止多个备份任务重叠执行)。
1 | // 案例:定期备份日志文件 |
3. 超时自动取消 (Self-Cancellation)
结合 ScheduledThreadPool,你可以实现一个简单的 “订单超时未支付自动关闭” 逻辑。
关键方法:schedule(仅执行一次)
1 | public void createOrder(String orderId) { |
4. 配合 CompletableFuture 实现超时控制
虽然 Java 9+ 的 CompletableFuture 自带了 orTimeout,但在 Java 8 中,我们通常配合 ScheduledThreadPool 来手动触发异步任务的超时。
1 | CompletableFuture<String> task = CompletableFuture.supplyAsync(() -> { |
避坑指南
异常捕获:ScheduledThreadPool 有个极大的坑——如果任务执行中抛出异常且没有被 try-catch 捕获,该任务将停止后续所有的循环执行,且不会有任何错误日志。所以任务内部必须包一层 try-catch。
线程数设置:如果所有任务都非常准时,核心线程数设为 1 即可;但如果有多个任务并行且有阻塞,建议根据任务量增加核心线程。
优雅关闭:程序停止时记得调用 shutdown(),否则后台线程可能阻止 JVM 退出。
1 | // 错误示范:一旦异常,定时任务永久失效!!! |
如果项目中有很多定时任务,每个都写 try-catch 太繁琐,可以写一个装饰器(Decorator):
1 | public class SafeRunnable implements Runnable { |
ForkJoinPool
工作原理
ForkJoinPool 是 JUC 家族中处理 “大任务” 的终极杀手锏。它是 Java 7 引入的,也是 Java 8 Parallel Streams(并行流)底层默认的动力源。它的的逻辑非常直观:
- Fork (拆分):如果任务太大,就递归地拆分成更小的子任务。
- Join (合并):等待子任务执行完毕,将结果汇总,逐层向上返回。
核心算法 - 工作窃取算法 (Work-Stealing):
在 ForkJoinPool 中,没有一个 Worker 会袖手旁观。它像是一个极度卷的团队:强者(Worker A)通过 Fork 把任务分细,而‘闲人’(Worker B)会主动去强者队列的最底层搬走最重的那块砖。这种‘双端队列 + 窃取’的机制,让 Java 能够榨干多核 CPU 的最后一丝性能。
- 普通线程池的弊端:如果一个线程分配到的任务很重,另一个很轻,轻的干完活后只能闲着(或者去全局队列抢活,产生锁竞争)。
- ForkJoinPool 的做法:
- 每个工作线程(Worker)都有自己的双端队列(Deque)。
- 线程自己产生的任务(Fork出来的)放在队列头部(LIFO,栈模式,提高缓存命中率)。
- 窃取行为:当线程 A 忙完了自己队列的所有活,它不会闲着,而是去线程 B 的队列尾部偷一个活来干(FIFO,减少与线程 B 的竞争)。
关键组件:
- ForkJoinPool:线程池管理者,负责接收任务并分配给 Worker。
- RecursiveTask:有返回值的任务。类似于 Callable。
- RecursiveAction:无返回值的任务。类似于 Runnable。
普通的递归是在同一个线程的栈帧中不断压栈,任务多了会 StackOverflow。Fork() 的本质是它是将任务 push 到了当前线程的 WorkQueue 中。如果当前 CPU 还有空闲核心,其他空闲线程会立刻过来 “窃取” 并并行处理,变伪递归为真正的 多核并行。
应用案例
计算一个包含 1000 万个数字的数组之和。
1 | public class SumTask extends RecursiveTask<Long> { |
避坑指南
避免在任务中进行 I/O 阻塞:ForkJoinPool 是为 CPU 密集型任务设计的。如果子任务在等待数据库或网络,会导致工作窃取失效,甚至导致全员阻塞。
合理设置阈值:如果 THRESHOLD 太小,拆分的开销(创建对象、入队出队)可能超过计算本身的收益;如果太大,则无法发挥并行的优势。
Join 的顺序:一定要先 fork() 完所有子任务,再统一 join()。如果你 fork() 一个紧接着 join() 一个,它就退化成了串行。