JUC包概览以及它和并发关键字们的比较
JUC包概览
在 Java 17 及其后续版本中,java.util.concurrent (JUC) 及其子包(atomic、locks)包含的类、接口、枚举和异常总数大约在 70 到 100 个 之间。这个包的设计非常精妙,可以被视作一个从 “硬件原子操作” 到 “高级应用框架” 的完整塔式结构。为了方便理解,我们可以将其大致分为以下 6 大类:
线程池与执行框架 (Executor Framework):
这是 JUC 中最常用的部分,它将任务的提交与执行解耦,解决了频繁创建线程带来的性能开销。
- 核心类:ThreadPoolExecutor、ScheduledThreadPoolExecutor、ForkJoinPool
- 关键接口:Executor、ExecutorService、Callable、Future
- 工具类:Executors(工厂类)
显式锁体系 (Locks):
在 java.util.concurrent.locks 包下,这是替代 synchronized 关键字的进阶方案,提供了比 synchronized 更灵活、更强大的锁机制,支持公平性选择、中断响应和超时机制。
- 核心类:
- ReentrantLock:最常用的可重入锁,支持公平/非公平锁、尝试加锁及中断。
- ReentrantReadWriteLock:读写锁,允许多个线程同时读,但只允许一个线程写。
- StampedLock:Java 8 引入,支持“乐观读”模式,性能比读写锁更高。
- Condition:等待/通知机制。
- 基础支撑:
- AbstractQueuedSynchronizer:AQS 是 JUC 的灵魂基类
- AbstractQueuedLongSynchronizer:长整型 AQS
- LockSupport:线程阻塞/唤醒原语
同步辅助类 (Synchronizers):
这些工具类用于控制多个线程之间的协作流转,比如让一组线程等待彼此,或者限制访问资源的线程数量。
- 核心类:
- CountDownLatch(倒计时器)
- CyclicBarrier(循环屏障)
- Semaphore(信号量/限流)
- Exchanger(双线程数据交换)
- Phaser(多阶段同步器)
- ThreadLocal(虽然不在 JUC 包,但并发开发必用)
原子操作类 (Atomics):
位于 java.util.concurrent.atomic 包下。它们利用底层硬件的 CAS (Compare And Swap) 指令实现无锁(Lock-Free)操作,保证了单变量操作的原子性。
- 基本类型: AtomicInteger、AtomicLong、AtomicBoolean
- 引用类型: AtomicReference、AtomicStampedReference(解决 ABA 问题)
- 数组相关:AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray
- 高性能累加: LongAdder 及 DoubleAdder(高并发下优于 AtomicLong)、LongAccumulator 及 DoubleAccumulator(自定义规则的累加)
- Unsafe:虽然在 sun.misc,但 JUC 处处在用它
并发容器(Concurrent Collections):
这些容器专门为高并发场景设计,通常通过分段锁或写时复制等技术,在保证线程安全的同时提供远高于 Collections.synchronizedXxx 的吞吐量。
- Map:ConcurrentHashMap、ConcurrentSkipListMap
- List/Set:CopyOnWriteArrayList、CopyOnWriteArraySet
- Queue:ConcurrentLinkedQueue、ConcurrentLinkedDeque
阻塞队列(Blocking Queues):
这是实现生产者-消费者模型的核心组件,也是线程池存储待执行任务的容器。
- 常用实现: ArrayBlockingQueue、LinkedBlockingQueue、LinkedBlockingDeque、PriorityBlockingQueue
- 特殊用途: SynchronousQueue (零容量直接交付)、DelayQueue (延时执行)
JUC 与 synchronized 们的比较
用户态内核态、上下文切换
用户态和内核态的本质区别在它们处于 CPU 内部的不同的状态位(在 x86 架构中,Ring 0为内核态、Ring 3 为用户态)。用户态就像商场的 “顾客”,只能在公共区域活动;内核态就像 “保安主管”,手里拿着所有房间的钥匙,可以进入配电房、监控室。当进程运行在 “用户态”时,CPU 的硬件逻辑(MMU)会拦截所有指向内核内存地址的请求。即便你的代码知道内核代码在内存的哪个位置,只要 CPU 标志位是 Ring 3,它就无法读取或写入那块内存。
操作系统为了保护系统安全,将处理器的运行模式分成了不同的级别。以 Linux 为例:
- 用户态 (User Mode):
- 这是应用程序(如你的 JVM、浏览器、IDE)运行的地方。
- 受限访问:不能直接访问硬件,不能直接操作内存管理单元(MMU)。
- 内核态 (Kernel Mode):
- 这是操作系统内核运行的地方。
- 最高权限:可以访问所有硬件资源(磁盘、网卡、内存)和特权指令。
用户态和内核态的关系,就像是 “顾客” 与 “银行保险库”:
- 内存:是存钱的地方(内核空间是保险库内部,用户空间是营业大厅)。
- 本质:是权限隔离。顾客(用户态)不能直接进保险库拿钱,必须填写申请单(系统调用),交给柜员(内核态),由柜员进入保险库操作。
这种 “填单子、排队、等柜员操作、拿钱” 的过程,就是你感受到的 “上下文切换开销”。只有理解了这一点,你才能明白 AQS 为什么要死磕 “用户态自旋”——如果能在营业大厅通过 CAS 互相协商好,就绝对不去排队找柜员!当 Java 线程请求一个被占用的重量级锁时,JVM 无法在用户态解决问题,必须向操作系统申请 “挂起当前线程”。这时就会发生模式切换(Mode Switch):
- 保存当前现场:记录用户态线程的寄存器、栈指针、程序计数器(PC)等数据。
- 切换 CPU 权限:CPU 从 Ring 3(用户态)切换到 Ring 0(内核态)。
- 执行内核代码:由内核处理互斥逻辑,将线程放入等待队列。
- 恢复现场:如果要运行另一个线程,需要从内存加载那个线程的上下文。
我们都知道切换上下文是一个 “很重” 的操作,“很慢”。这是为什么呢?本质上是因为:
- 寄存器与栈的保存恢复 (直接开销):虽然保存几十个寄存器只需要纳秒级,但频繁切换累加起来就很可观。
- 缓存失效 (间接开销 - 最致命):这是性能下降的主因。
- TLB (Translation Lookaside Buffer) 失效:内核态和用户态的虚拟内存映射不同,上下文切换后,地址转换缓存(TLB)会部分失效。
- L1/L2 Cache 污染:内核代码运行会把用户态程序的常用数据从 CPU 高速缓存中 “顶” 出去。当 CPU 切回用户态时,程序会面临大量的 Cache Miss,必须去慢速的内存(RAM)里重新读取数据。
- 调度器的参与:一旦进入内核态,操作系统的任务调度器(Scheduler)可能会介入,重新决定谁该运行。这种决策算法(如 Linux 的 CFS)本身也消耗 CPU 周围。
Lock 和 synchronized
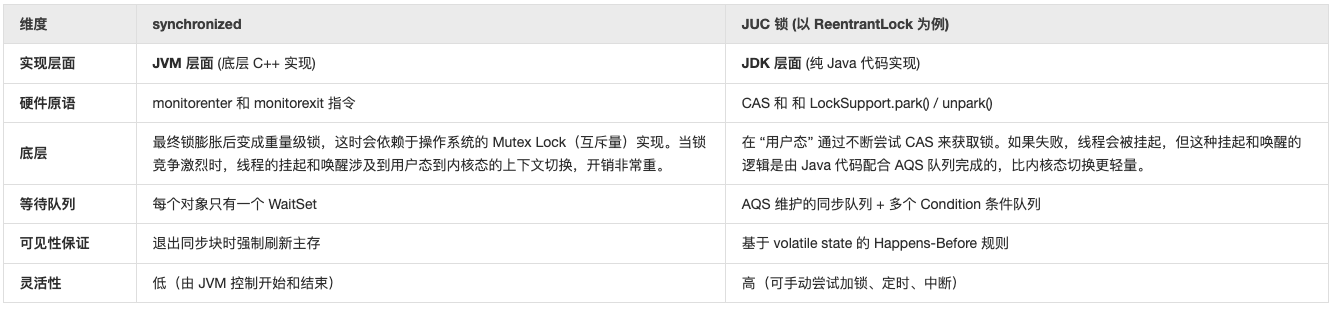
它们是如何 “记住” 谁拿到了锁的?
synchronized:标记在对象头上(请参考《JVM加载类的详尽过程》),每个 Java 对象都有一个 Mark Word(对象头的一部分)。锁的状态 → 【无锁】→【偏向锁 Java18正式废除】→ 【轻量级锁】 → 【重量级锁】,全都记录在这里。ReentrantLock:JUC 的锁(如 ReentrantLock)并不改变对象的 Mark Word。它内部维护了一个state变量(代表锁状态)和一个双向同步队列(CLH 队列)。- state == 0:锁空闲。
- state > 0:锁被占用(如果是可重入锁,数值代表重入次数)。
JVM 对 synchronized 做了自动化优化。锁可能会经历锁膨胀的不可逆升级过程。这种 “自动挡” 模式让开发者无需操心,但缺乏干预手段。而 JUC 锁是 “手动挡”。你可以通过 CAS 进行自旋等待,也可以使用 LongAdder 那样的分段思想减少竞争,甚至可以控制是公平锁还是非公平锁。
从上下文切换的角度来看, JUC 的 ReentrantLock 之所以能在高并发下表现更出色:本质上是因为它在 AQS 内部通过大量的CAS自旋尝试在 “用户态” 就把问题解决掉,只有在万不得已(自旋多次失败)时,才会调用 LockSupport.park() 进入内核态挂起线程。这就好比 Synchronized 一产生矛盾马上给警察(内核)打电话,警察开车过来处理,而 JUC/CAS 产生矛盾先在门口(用户态)互相协商(自旋),协商好了就各走各路,实在打起来了再叫警察。
LockSupport 和 wait/notify
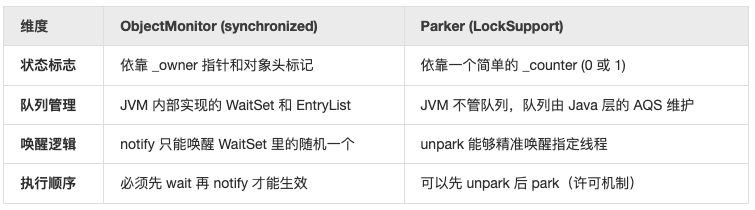
在 HotSpot 中,synchronized 对应的是 ObjectMonitor,synchronized 的重量级锁是一个复杂的管程模型,它内部维护了 _WaitSet(等待队列)和 _EntryList(锁竞争队列),由 JVM 严格管理节点状态。
1 | void ObjectMonitor::enter(TRAPS) { |
LockSupport.park 最终通过 Unsafe.park 调用到 JVM 内部每个线程持有的 Parker 对象。
src/hotspot/os/linux/os_linux.cpp:在 Linux 系统的 HotSpot 虚拟机中,park 的底层实现本质上是:一个原子条件变量(_cond) + 一个互斥锁(Mutex) + 一个计数器(_Counter)。
1 | // a. Java 层:执行 LockSupport.park()。 |
为什么 park 能先 unpark?
这是 park 区别于 synchronized-wait 的最底层的原因:
- Object.wait():底层没有 _counter。如果你先调用 notify(),由于此时没有线程在等待队列里,这个通知会直接永久丢失。后续再调用 wait() 依然会死锁。
- LockSupport.park():底层有一个 _counter 标志位。如果你先调用 unpark(),它会把 _counter 置为 1。等线程执行到 park() 时,一看 _counter 是 1,直接改成 0 就回去了,根本不去排队。
JUC LockSupport 的精髓在于:把复杂的 “排队逻辑” 和 “竞争逻辑” 用 Java 代码(AQS)在用户态写好了。只有在最后需要让线程真正 “睡觉” 的那一刻,才调用 Parker::park 这种极简的代码。synchronized-wait 则是将 “同步逻辑” 和 “线程阻塞” 全部打包丢给了内核。LockSupport.park 仅仅是把 “线程阻塞” 这个原子动作交给了内核,而 “同步逻辑” 和 “排队策略” 保留在了 Java 用户态的 AQS 中。这也是为什么很多高性能系统底层大量使用 AQS 的原因——它在保持灵活性的同时,最大限度地减少了非必要的内核干预。
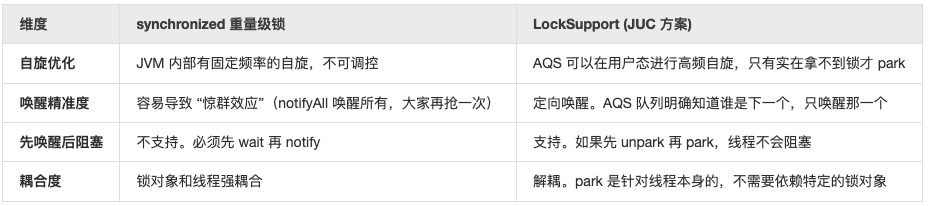
LockSupport.park 和 synchronized wait/notify 两者的核心差异总结如下表:
synchronized 是为了 “好用” 和 “稳定”: 它把复杂的并发控制封装在 JVM 内部,给普通开发者提供一个简单、安全、几乎不会出错的同步手段。它是 Java 的基础设施。LockSupport 是为了 “强大” 和 “灵活”: 它是给 JDK 大牛(如 Doug Lea)用来构建 AQS、线程池等高级工具的。它不需要像管程那样绑定在某个对象上,它直接操作线程,提供了极致的灵活性。
自旋和挂起
自旋的本质:while + CAS,在代码层面的直观表现如下:
1 | // 这是一个典型的自旋抢锁逻辑 |
为什么自旋能提高性能呢?核心在于它避开了上下文切换。正如我们之前说过的,上下文切换(Context Switch)的代价极其昂贵(保存现场、内核态切换、TLB刷新、Cache污染)。而自旋的逻辑依据是: 在多核 CPU 环境下,很多锁的占用时间其实非常短(比如只是为了增加一个计数器)。
- 场景 A(挂起):线程抢锁失败 → 切换到内核态 → 挂起(耗时 10ms)。等锁释放了再唤醒,总共可能消耗了几千个时钟周期。
- 场景 B(自旋):线程抢锁失败 → 在用户态循环 50 次 → 发现锁释放了 → 抢锁成功。总共可能只消耗了几十个时钟周期。
自旋用 CPU 的运算时间换取了内核态切换的开销。只要自旋等待的时间小于上下文切换的时间,系统整体吞吐量就会大幅提升。当然如果锁被一个线程占用了很长时间(比如在做大量的 I/O 操作),其他线程一直自旋下去,白白榨干 CPU 资源也是不合适的。因此现代 JVM 和 JUC 实现的是 “适应性自旋” (Adaptive Spinning):
- 限次自旋:旋转一定次数(比如 10 次)还没拿到锁,就老老实实去调用 park() 挂起。
- 智能判断:如果 JVM 发现这个锁上次自旋成功了,那么这次就会允许它多旋转一会儿;如果上次几乎没成功过,这次可能直接跳过自旋去挂起。
真正的工业级自旋不会只写 while(true),在汇编层面会加入 PAUSE 指令。PAUSE 指令能防止 CPU 因为过度频繁地读取同一个内存地址而导致流水线清空(Pipeline Flush),从而降低功耗并让出一定的资源给其他逻辑核心。
1 | // 伪代码:HotSpot 中的自旋片段 |
| 维度 | 自旋 (Spinning) | 挂起 (Blocking/Parking) |
|---|---|---|
| 状态 | 运行态 (Running),占用 CPU | 等待态 (Waiting),释放 CPU |
| 开销 | 消耗 CPU 指令,无切换开销 | 极低功耗,但有沉重的切换开销 |
| 适用场景 | 锁占用时间极短、多核 CPU | 锁占用时间长、单核 CPU (单核自旋无意义) |
AQS acquireQueued 示例
这是并发编程领域最著名的 “极限拉扯”。该方法完美展示了如何在高并发下平衡 “应用性能” 与 “资源占用”。在 AQS 中,线程被封装成 Node 放入双向链表队列。当一个线程进入队列后,它并没有立刻 “睡觉”,而是在自旋与阻塞之间做决定。以下是 AbstractQueuedSynchronizer 中该方法的简化逻辑:
1 | final boolean acquireQueued(final Node node, int arg) { |
这个方法的精妙之处在于它不是简单的 while(true),而是一个有策略的自旋。
- 第一层:身份检查(资格自旋)。只有 “node.predecessor() == head” 的线程才会去尝试 tryAcquire。目的是避免 “惊群效应”。如果队列里有 1000 个线程,锁释放时,只有排在最前面的那个人会去抢,其他人在后面安心睡觉。这极大地减少了无谓的 CPU CAS 竞争。
- 第二层:挂起预检(shouldParkAfterFailedAcquire)。在真正调用 park() 之前,线程会检查前驱节点的状态。如果前驱节点状态是 SIGNAL(表示前驱释放锁时会通知我),那么我就可以放心地 park() 了。如果状态不对,我会再试着清理一下队列或者再自旋一次。
- 第三层:进入阻塞(parkAndCheckInterrupt)。如果前两步都失败了,说明锁一时半会儿放不出来,此时线程调用 LockSupport.park(),此时线程才真正进入内核态挂起,让出 CPU 给别人。
为什么不直接 park,而是非要先 “自旋” 一下?可以想象一下,如果前一个线程拿到锁之后,只执行了一行代码 “count++” 就释放了。
- 直接挂起方案:你抢锁失败 → 挂起(进内核) → 前面释放锁 → 唤醒你(进内核)。这两次内核切换可能花了 20 微秒。
- AQS 方案:你抢锁失败 → 发现你是 “二当家” → 你在 for(;;) 里转了半圈 → 刚好前面释放了 → 你抢到了。整个过程只花了 0.1 微秒,性能差距高达 200 倍。
AQS 的 acquireQueued 是一个典型的 “用户态缓冲策略”:
- 抢锁:先用 CAS 试一下(万一能捡漏呢)。
- 排队:捡漏失败,乖乖进队列。
- 自旋:进了队列发现自己排在第一顺位,再试一下(万一前面那个大哥刚好办完业务呢)。
- 挂起:实在不行了,找个地方睡觉(park),等前面的人拍拍你(unpark)。
这就是为什么 JUC 能够承载高并发的本质:它通过复杂的 Java 逻辑(用户态),精准地算计着每一次进入内核态的成本。
JUC 能否替换并发关键字们?
简单直接的回答是:JUC 在功能上完全可以替代 synchronized,但在实际开发中,它们更多是 “互补” 关系,而非 “有你没我” 的淘汰关系。
1. 性能的 “反转”:从碾压到平齐
在 Java 1.5 刚引入 JUC 时,ReentrantLock 的性能确实远超 synchronized。但随着 JVM 的不断优化,情况发生了变化:
- 早期(Java 1.5 以前):synchronized 是“重量级锁”,直接依赖操作系统的互斥量(Mutex),挂起和唤醒线程开销巨大。
- 中期(Java 1.6 优化):JVM 引入了偏向锁、轻量级锁、锁消除、锁粗化等技术。
- 现状:在竞争不激烈的情况下,synchronized 的性能由于有 JVM 的原生支持(如自偏向),往往比 ReentrantLock 更优或持平。只有在极高竞争下,JUC 的显式锁才表现出更稳定的吞吐量。
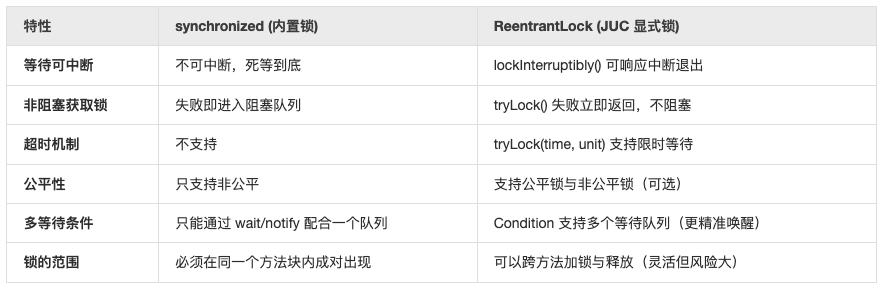
2. 功能维度的对比:JUC 的 “降维打击”
虽然 synchronized 简单好用,但 JUC 提供的 Lock 接口在功能上是降维打击,它解决了 synchronized 无法处理的三个痛点:
3. 为什么 synchronized 依然不可替代?
既然 JUC 这么强,为什么不全面废除 synchronized?
- 代码简洁性: synchronized 是语法层面的,自动加锁释放,不会出现由于忘记 unlock() 导致的死锁。
- JVM 深度优化:JVM 可以感知 synchronized 的状态。例如,如果 JVM 发现一个锁对象只被一个线程访问,它会直接通过锁消除来提升性能,而 JUC 类库很难被这种编译器级别的优化覆盖。
- 内存开销: synchronized 是对象头里的几个位(Mark Word),而 ReentrantLock 是一个实实在在的对象,需要分配内存。
- 官方态度:Java 官方一直在优化 synchronized(如 Java 15 禁用了偏向锁,但在更高版本中持续改进线程调度),它是 Java 并发的 “亲儿子”。
实际应用该怎么选?
在实际项目中,当你需要极致的代码简洁性,且并发量不是天文数字时。现代 JVM 的 “逃逸分析” 可以对 synchronized 做锁消除优化,这是 JUC 锁做不到的。以下情况必须使用 JUC (ReentrantLock 等):
- 高竞争场景:锁竞争非常激烈,需要更稳定的吞吐。
- 复杂逻辑:需要用到 tryLock 避免死锁,或者需要根据不同条件(Condition)唤醒特定线程(如生产者-消费者模型)。
- 读写分离:明确的读多写少场景(使用 ReentrantReadWriteLock)。