算法世界的大致图景
算法世界的基石
算法设计首要因素
在深入五大版图之前,我们需明确:所有的算法设计,首先需考虑两个终极要素——数据结构 与 复杂度权衡。
算法的每一步操作,本质上都是在数据结构上进行读写,结构决定了算法的上限。如果你用数组存数据,查找再快也快不过 $O(n)$;如果你进化到了红黑树,查找立刻就能降到 $O(\log n)$。
算法是一门关于 “舍得” 的艺术,世界上没有完美的算法,只有在当前环境下最合适的算法。比如你现在要从北京去上海:你可以步行,不花钱但要走一个月;也可以坐高铁,花点钱几小时就到;私人飞机更快,极贵但起飞即达。权衡的本质就是:
- 时间与空间的博弈:比如哈希表,它查找极快【$O(1)$】,但代价是它非常占内存。这就是用
空间换时间。 - 精度与速度的博弈:有些问题求精确解需要算一百年,我们用概率算法算 1 秒得出一个 99% 正确的近似解。这就是
用准确度换速度。
当你把这两者结合起来时,你会发现所有的算法研究其实都在干同一件事:在特定 “效率权衡” 的要求下,寻求一种最契合的 “数据组织” 方式。
- 排序算法:是为了把无序的数据组织成有序,从而为之后的查找节省时间。
- 红黑树:是为了在插入和删除数据时,通过复杂的逻辑组织,强行保证查找的复杂度永远稳定在 $O(\log n)$。
- 动态规划:是通过建立 “备忘录”(一种数据组织),把重复计算的时间省下来(效率权衡)。
所有算法的底层思想
无论是哪种算法,它们都建立在以下三个 “元思想” 之上:
- 迭代与递归:解决问题的基本循环模式。
- 空间换时间:为了快(查找),我们愿意多花内存(建树、建哈希表)。
- 复杂度分析 ($O$):这是评价所有算法优劣的唯一客观尺标。
最基础的两种算法
排序和搜索。之所以说这两种算法最基础,是因为它们的使用频次最高。排序和搜索就像是人体的神经末梢和毛细血管一样,在程序的世界中无处不在。
排序(sort):建立秩序的起点
排序不仅仅是将数字按大小排列,它的本质是 消除熵值(无序度)。排序本质上是在建立规则。计算机对杂乱无章的数据几乎无计可施。通过排序,我们将数据从 “熵值” 极高的状态转化为有序状态,这为后续所有高级算法(如二叉搜索、动态规划的子问题划分)提供了可预测的逻辑前提。
查找(search):获取价值的终点
查找本质上是在获取价值。数据的存在如果没有被检索到,就毫无意义。红黑树、哈希表、B+树,这些精妙的设计全部是为了一个目标:在最坏的情况下,也能以极快的速度找到那个正确的值。
五大核心算法范式
如果说排序和查找是手中的工具,那么五大核心范式就是你大脑中的解题策略。之所以称它们为 方法论,是因为它们不是具体的代码模板,而是当你面对一个陌生难题时,拆解问题、建模数据、权衡开销的一套思维路径。
递归与分治
它是大部分复杂算法的 “母题”。当你面对一个庞大的数据集时,不要试图一眼望穿,而是问自己:“如果我能解决其中一半,剩下的一半是否逻辑一致?”。在现代算法中,无论是快速排序、归并排序,还是二分搜索、红黑树,本质上都是分治思想。它教会了计算机如何处理 自相似 的复杂性。
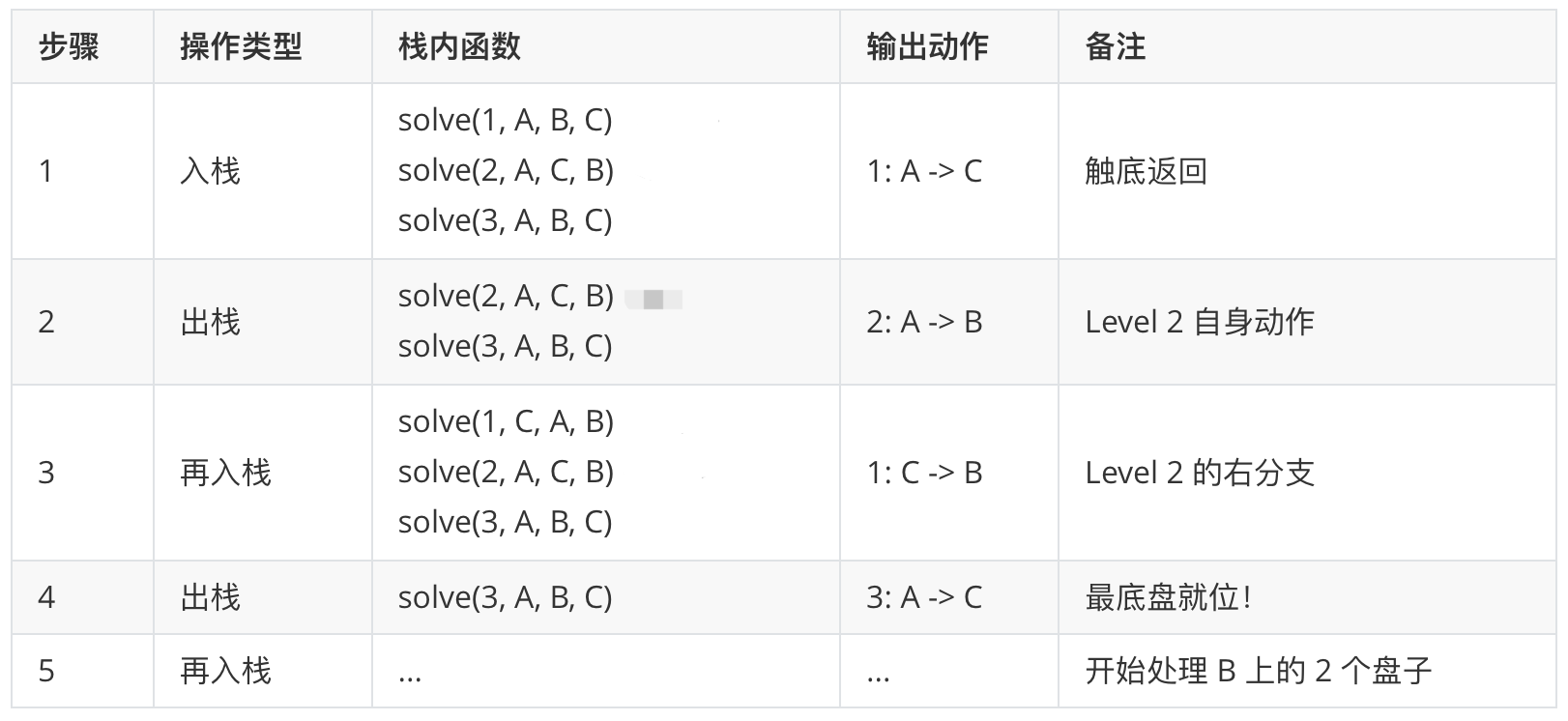
递归代言人:汉诺塔。汉诺塔完美诠释了递归的两个核心:
- 自相似性:移动 $3$ 个盘子的过程里,包含移动 $2$ 个盘子的过程;移动 $2$ 个的过程里,包含移动 $1$ 个的过程。
- 信任链:在写 hanoi 方法时,你不需要纠结具体的每一步怎么挪。你只要信任这个函数能处理 n-1 的情况,并在这个基础上完成第 n 个的动作即可。
1 | /** |
注意:递归虽然代码简洁,但如果“进场”太深($n$ 太大),会导致栈溢出(Stack Overflow)。这就是为什么我们在 “效率权衡” 中,有时不得不放弃递归的优雅,转而使用迭代(循环)的原因。
分治代言人:归并排序
1 | public static void mergeSort(int[] array) { |
注意:递归与分治并不是对立的,而是一对相互协作的策略。递归的本质是函数的自我调用,它是一种编程技巧,核心在于定义 “边界条件” 和 “递推公式”,可以将递归比喻成一个 “俄罗斯套娃”,每一层都在做同样的事,直到看到最里面的那个小娃娃。分治的本质是处理问题的思维框架,它强调的是 “分而治之”。如果说递归是纵向爆破问题,那么分治就是水平拆分问题。
深度和广度优先搜索
该范式是人类探索 “可能性” 的最基本方式。 它的核心思想是 “所有的选择题本质上都是一棵树”。要点在于在未知的空间里,建立一套不重复、不遗漏的坐标系。
- DFS 是 “执着者”:我先选定一条路走到死,不通再换。这对应了逻辑推理中的自洽性证明。
- BFS 是 “掌控者”:我先看清所有近在咫尺的机会,再稳步向外扩张。这对应了现实中 “最优步数” 的寻找。
贪心算法
在特定约束下,相信 “当下最好” 就是 “最终最好”。用最少的计算,博取当下最大的确定性。 这是一种极高效率的降级处理。它不去推演未来一万步,只求这一步性价比最高。虽然它在很多领域会失效,但在特定结构(如最小生成树)中,它是最快的路径。
动态规划
该方法的核心是:拒绝做无用功,用空间锁死时间。这是最硬核的方法论,它要求你发现问题中的 “重叠” 性。如果昨天的路已经走过了,为什么今天还要再走一遍?通过建立备忘录(数据组织),我们将计算的熵减到了极致。它的哲学是 “凡走过必留下痕迹,凡计算过必化为知识”。
如果要选出一个能够代表 DP 灵魂的典型,那肯定就是 “背包问题”,尤其是其中的 0-1 背包。因为它完美地诠释了 DP 的核心方法论:通过存储子问题的解,来消除重复计算。
问题描述:你有一个容量有限的背包和一堆价值、重量各异的物品。每件物品只有 “拿” 或 “不拿” 两种选择。如何在不撑爆背包的前提下,带走价值最高的组合?
如果你用递归去试每一种组合,复杂度是 $O(2^n)$,物品稍多就会算到天荒地老。而 DP 方法是通过建立一张 “备忘录表”——横轴是背包容量,纵轴是物品。表里的每一个格点,都代表了 “在当前容量下,处理完当前物品能拿到的最大价值”。它向我们展示了——未来的最优决策,必然建立在过去的最优结果之上。你不需要重新计算,只需要查表,这就是 “记忆化” 的威力。
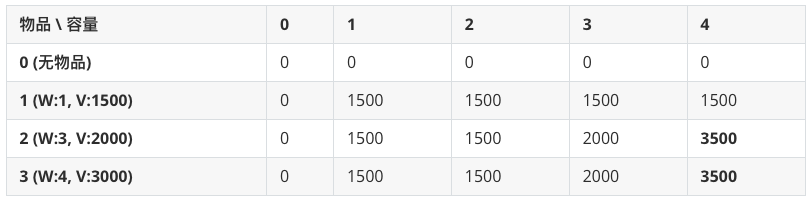
① 第一行和第一列全是 0,这是初始状态:如果背包容量为 0,无论物品多值钱也装不下,价值为 0;如果没有物品可选,无论背包多大也装不到东西,价值为 0。
② 每一个格点的计算逻辑(状态转移):以 “物品 2 (W:3, V:2000),容量 4 的位置(值为 3500)” 为例。当算法运行到这里时,它面临一个决策:
- 不拿物品 2:那么最大价值就等于上一行同容量的值,即 $dp[1][4] = 1500$。
- 拿走物品 2:
- 首先,我们要为物品 2 腾出 3 个单位的空间。
- 腾出空间后,剩下的容量是 4 - 3 = 1。
- 我们去查表,看容量为 1 时,处理完前一个物品(物品 1)的最大价值是多少?查表得 $dp[1][1] = 1500$。
- 总价值 = 物品 2 的价值 (2000) + 剩余空间的最大价值 (1500) = 3500。
这一步的决策结果:$\max(1500, 3500) = 3500$。
③ 最终答案:就在表的最后一行,最后一列,这就是我们要的全局最优解。在本例中是 3500(拿走物品 1 和物品 2)。
你看,传统的递归会反复询问 “容量为 1 时装物品 1 价值多少?”。而 DP 只算一次,然后把结果永久记录在格子里。当你填满最后一行时,你实际上已经穷举了所有可能的组合,但你并没有通过粗暴的排列组合去算,而是利用了 “已知的局部最优” 来推导 “未知的整体最优”。填表的过程本质上是在进行一场时空回溯:算法每走一步,都会回头查看之前的最优记录。这种 站在巨人肩膀上 的迭代,让原本随着物品数量指数级增长的计算量,被死死地锁定在了 “物品数量 × 背包容量” 的线性空间内。这就是记忆化对计算维度的降维打击。
1 | /** |
测试结果:
1 | 0 0 0 0 0 |
双指针与滑动窗口
精髓在于避免无效的全局遍历,通过改变观察视角来优化效率,你可以理解成 “在运动中寻找平衡,在局部中洞察全局”。既然数据是线性排列的,我可以用两个 “探针” 框定一个范围。随着范围的移动或缩放,我只需要处理进出的元素,而不需要重新扫描框内的所有东西。
算法世界的六大版图
基础策略类算法
这一版图不关注具体的数据类型,而是关注解题的思维范式。
- 分治法 (Divide):将难题切碎。如快速排序。
- 贪心 (Greedy):只看眼前的最优解。
- 动态规划 (DP):通过存储子问题的解,避免重复计算,处理具有“重叠子问题”的复杂抉择。
图论算法
图论处理的是关系,只要有节点和连线就是图。
- 路径规划:比如导航软件寻找最短路径。
- 网络流:比如供水系统的流量分配、电路板的设计。
- 搜索技巧:DFS(深度优先)和 BFS(广度优先)是图论的灵魂。
字符串算法
人类社会绝大多数信息以文本形式存储,如何从海量文本中定位关键词?
- 模式匹配:KMP 算法、AC 自动机。
- 数据压缩:Huffman 编码,让文件变小。
- 生物信息:对比基因序列的相似性。
数值与数学算法
处理纯粹的数字,往往涉及高深的数学原理。
- 加密算法:RSA 等保护隐私的基石。
- 大数运算:计算机硬件无法直接处理的超长数字计算。
- 概率模拟:蒙特卡洛模拟,用概率解决确定性的问题。
计算几何
在 3D 游戏、自动驾驶、物理碰撞检测中,我们需要处理空间坐标。
- 凸包问题:寻找包围点群的最小多边形。
- 碰撞检测:判断两个物体在空间中是否接触。
机器学习与神经计算
第一,优化学习类 (Optimization):通过损失函数寻找全局最小值。
- 梯度下降 (Gradient Descent):不断微调参数以减少误差。
- 反向传播 (Backpropagation):神经网络学习的灵魂。
第二,生成与概率模型 (Generative Models):不仅是处理数据,更是创造数据。
- Transformer 架构:现代大语言模型(LLM)的基石,利用“注意力机制”理解上下文。
- Diffusion 扩散模型:生成式绘图背后的核心数学逻辑。
第三,强化学习 (Reinforcement Learning):模仿人类的“奖励-惩罚”机制。
- Q-Learning / PPO:在不断尝试中学习策略。如 AlphaGo 战胜棋手,机器人学习行走。