Redis 原生技术栈的介绍以及 RediSearch 和 RedisJSON 的编译安装(基于Redis 8.2)
Redis 原生技术栈是什么
Redis Stack 是 Redis 官方推出的一套集成化技术栈,它通过扩展 Redis 的核心功能,将其从一个简单的 “键值对缓存” 提升为一个多模态(Multi-model)现代数据库。
简单来说:Redis Stack = Redis 核心 + 一系列高性能模块 + 管理工具。
为什么需要 Redis Stack?
传统的 Redis 主要用于缓存。但随着应用复杂化,开发者希望在 Redis 中直接处理复杂的 JSON 数据、进行全文搜索或向量检索。以往你需要手动编译和加载各种插件,而 Redis Stack 将这些最常用的增强功能开箱即用地打包在了一起。
Redis Stack 的核心组件
目前它主要由以下四大支柱组成:
① RedisJSON(灵活的文档存储)
- 功能:允许以原生方式存储、更新和检索 JSON 文档。
- 优势:支持 JSONPath 语法,更新时只需修改文档的某个字段,无需像传统 Hash 那样序列化整个对象。
② RediSearch(强大的搜索引擎)
- 功能:在 Redis 上实现类似 Elasticsearch 的功能。通过倒排索引检索查询,相比传统的需扫描所有 “Key (KEYS *)”,效率大幅跃升。
- 特性:
- 全文搜索:支持分词、模糊匹配。
- 二级索引:可以对 Hash 或 JSON 的字段创建索引。
- 聚合查询:支持 Group By、排序等操作。
- 向量搜索 (Vector Search):这是目前 AI 领域(如 RAG 架构)的核心,支持高效的相似度计算。
③ RedisTimeSeries(时间序列数据)
- 功能:专门处理时序数据(如监控指标、物联网传感器数据)。
- 特性:内置降采样、自动过期设置和高效的压缩算法。
④ RedisBloom(概率性数据结构)
- 功能:提供布隆过滤器(Bloom Filter)、布谷鸟过滤器等。
- 应用场景:极低内存消耗下判断 “某个元素是否存在”,常用于防止缓存穿透。
生态系统工具
除了服务端模块,Redis Stack 还包含了提升开发者体验的工具:
Redis Insight:一个非常强大的图形化管理桌面工具。你可以直接在界面里可视化查看 JSON 结构、调试搜索索引、监控系统负载。
客户端库 (Redis OM):针对 Python, Node.js, Java 等语言提供的对象映射库(类似 ORM),让操作 JSON 和搜索变得像操作本地对象一样简单。
RediSearch v8.2.0 的编译安装
RS 与 ES 的检索效率对比
编译之前,我们先来对比一下 RediSearch 和 ElasticSearch 的检索查询效率数据对比。根据 Redis 官方以及多项第三方基准测试(如使用 Wikipedia 数据集),在同等规格的硬件条件下,两者的表现如下:
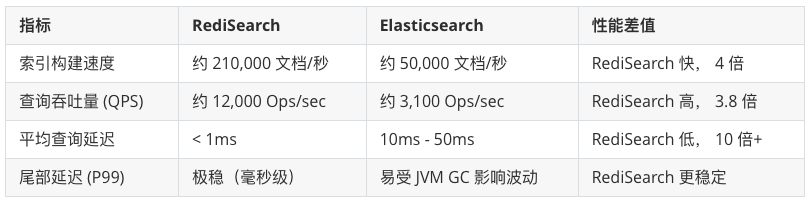
核心结论:
- RediSearch 在 高并发、低延迟 的场景(如电商实时搜索、秒杀库存检索)中完胜;
- 而在海量数据(PB级)和复杂聚合分析场景下,ES 依然是王者。
RS 与 ES 核心优劣深度对比
RediSearch (基于内存的实时检索利器)
- 优势一 - 极致的性能:数据驻留在内存中,利用 Redis 的单线程(及多线程 I/O),消除了磁盘 I/O 等待。
- 优势二 - 实时性:索引更新是同步的,数据写入即刻可见,不存在 ES 那样的 refresh_interval(默认 1 秒)延迟。
- 优势三 - 内存效率:使用压缩倒排索引,内存占用通常比原生 Redis 存储 Hash 还要低。
- 优势四,AI 友好:内置的高性能向量搜索 (Vector Search) 是目前 RAG 架构的首选,性能远超 ES 的向量插件。
- 劣势一 - 成本较高:所有数据必须进内存,存储 PB 级数据的成本远高于磁盘。
- 劣势二 - 查询复杂性稍逊:虽然支持聚合,但对于极其复杂的关联分析、多层嵌套聚合,不如 ES DSL 强大。
- 劣势三 - 生态圈目前较小:比起 ES 庞大的 ELK 家族,可视化和日志采集工具链稍显单薄。
Elasticsearch (海量数据的分布式标准)
- 优势一 - 海量存储:基于 Lucene,支持通过磁盘(SSD)存储 PB 级数据,成本曲线更平滑。
- 优势二 - 强大的分析能力:其聚合引擎(Aggregations)极其强大,非常适合做数据报表、大屏看板。
- 优势三 - 成熟度高:拥有极强的分布式水平扩展能力(分片、副本机制非常成熟)。
- 优势四 - 生态无敌:Kibana、Logstash、Beats 的组合让它在日志分析(L-Log)领域不可替代。
- 劣势一 - 资源消耗大:基于 JVM,堆内存管理复杂,垃圾回收(GC)容易导致查询毛刺(Latency Spike)。
- 劣势二 - 索引延迟:默认有 1 秒的近实时延迟,不适合对强一致性要求极高的场景。
- 劣势三 - 配置复杂:分片设置(Sharding)不当会导致严重的性能下降或集群崩溃。
使用场景决策
选择 RediSearch 的情况:
- 实时搜索:如 APP 搜索框提示、实时商品库检索。
- 高频更新:数据每秒修改上千次,且要求修改后立即能被搜到。
- AI/LLM 应用:作为向量数据库存储 Embedding,追求毫秒级召回。
- 轻量级部署:你已经在用 Redis,不想再额外维护一套复杂的 ES 集群。
选择 Elasticsearch 的情况:
- 日志系统 (ELK):处理海量非结构化日志数据。
- 复杂报表:需要进行多维度、深层次的数据统计。
- 数据归档:需要存储过去 3-5 年的历史数据,且不经常查询。
RediSearch 的编译安装
Redis 官方其实已经提供了 Redis Stack 等方便的集成安装部署的方式(包含 Docker 镜像、DEB/RPM 安装包 等),按理说应该像安装普通软件一样简单,但在生产环境,尤其是你可能基于 CentOS 7 的物理环境中,手动编译往往是 “不得不做” 或 “为了极致性能而做” 的选择。更关键的是,在官方网站你可以看到,Redis Stack 往往落后于当前的最新版本,为了在 redis 8+ 使用 RediSearch 等功能,我们不得不对相关 module 进行源码编译集成。
我当时使用的操作系统是 CentsOS7。实话说,编译 RediSearch 8.2.0 是一件极其繁琐、细致的工作,非常容易出现各种各样的问题,所以如果你要是准备以这种方式集成 RediSearch,务必要有充足的心理准备。这里我们只记录了一些关键的编译步骤,如果你的编译过程中有出现其他问题,请移步xxx。废话结束,我们开始!
第一阶段:系统基础环境与 Repo 修复
由于 CentOS 7 官方源即将停服,必须先将源指向 vault 归档站。
1 | # 1. 备份并清理旧源 |
第二阶段:升级核心编译工具链 (Make & CMake)
RediSearch 8.0+ 的构建脚本要求 Make 4.0+ 和 CMake 3.20+。
1 | # 1. 安装基础构建工具 |
第三阶段:安装现代编译器 (GCC 11 & LLVM 12)
Redis 8.2 的高性能矢量搜索(Vector Search)需要支持 C++20 的 GCC,而 Rust 绑定需要 libclang。
1 | # 1. 安装 GCC 11 (devtoolset-11) |
第四阶段:源码获取与子模块同步
注意: RediSearch 强烈依赖子模块,必须完整拉取。
1 | # 克隆并切换到 v8.2.0 (根据你之前确认的版本) |
第五阶段:编译与安装
方法 A:使用官方脚本 (推荐,但是经常报错)
1 | ./build.sh --release |
方法 B:手动 CMake 编译 (针对高级配置,相对顺利)
1 | # 在源码根目录下(我这里是 /root/installpack/RediSearch) |
如果看到 redisearch.so,恭喜你大功告成!
第六阶段:Redis 配置加载
编译完成后,将生成的 .so 文件移至 Redis 模块目录。
1 | # 1. 复制模块 |
RediSearch 生产环境参数配置建议
作为 Redis 的模块,RediSearch 的配置参数是在加载模块时通过 loadmodule 指令传递的。由于 RediSearch 在生产环境中非常消耗内存且涉及多线程操作,合理的参数配置直接决定了系统的稳定性。
在你的 redis.conf 中,配置格式如下:
1 | loadmodule /etc/redis/modules/redisearch.so [参数名] [参数值] ... |
以下是常用的核心参数:
NTHREADS:建议值 4 或 8。多线程搜索。默认值为 3。在多核服务器上,增加此值可大幅提升复杂查询的 QPS。建议设为物理核数的 1/2。MAXSEARCHRESULTS:建议值 1000。最大返回结果数。防止由于错误的查询请求导致 Redis 试图返回百万级数据而引发网络 IO 阻塞或 OOM。TIMEOUT:建议值 500。查询超时(毫秒)。防止某个极端复杂的查询(如深度嵌套的模糊匹配)长时间占用 CPU。超时后会返回已搜到的部分结果。- MAXIDLE:建议值 10。索引扫描最大空闲时间。如果索引任务非常重,设置此值可让搜索任务在后台扫描时更频繁地释放 CPU,防止 Redis 出现瞬时卡顿。
- CONCURRENT_WRITE_OPTIMIZATION:建议值 1。并发写优化(针对 v2.x+)。开启后,在进行大量索引写入时,能更好地平衡查询性能,减少写锁竞争。
- PARTIAL_INDEX_CLEANUP:建议值 1。增量清理。允许在后台逐步清理已删除文档的索引残余,保持内存整洁而不触发昂贵的全局重建。
- MIN_PHONETIC_TERM_LEN:默认值通常为 3。最小语音项长度,这个参数与语音匹配功能配合使用。语音匹配允许用户搜到“听起来像” 的词。例如搜索 Smith 时,也能搜到 Smyth。它规定了开启语音算法处理的最小单词长度。如果长度太短的话,语音算法会产生大量的误配,语音匹配比普通字符匹配更耗 CPU。生产环境可以保持默认值 3。如果你的数据包含大量极短的专业术语,且误报率太高,可以将其调大到 4。
- MAXEXPANSIONS:默认值通常为 200。最大查询扩展数,这个参数主要限制模糊匹配 (Fuzzy Matching) 或 通配符查询所能展开的最大单词数。当你使用
TEXT字段进行模糊搜索(如FT.SEARCH idx "hell%")或相似度搜索(Levenshtein 距离,如FT.SEARCH idx "%%hello%%")时,RediSearch 会在索引中寻找所有符合条件的词。这个参数决定了它最多找多少个匹配项。如果你搜索a%(匹配所有以 a 开头的词),索引中可能有几万个符合条件的词。如果没有限制,Redis 会尝试处理这几万个分支,导致主线程卡死(STW - Stop The World)。而且过度的扩展通常也会导致搜索结果极不精准。生产建议设为 100 以确保极致的响应速度。 - GC_POLICY:默认值是 FORK。RediSearch 在更新数据时,旧的索引条目不会立即从内存物理删除,而是打上标记。
GC负责清理这些死数据。 - KEEPEVECTED:这是一个比较冷门的参数。正常情况下,如果 Redis 因为内存不足(Eviction)删除了一个 Key,RediSearch 会同步从索引中删除它。开启此参数后,即使 Key 被删了,索引可能还会保留(但通常不建议在生产中开启,除非有极其特殊的离线分析需求)。
- BACKLINK:反向链接,默认开启且深度集成。这是 RediSearch 内部的一种索引结构。它在索引条目和原始 Hash/JSON 键之间建立双向映射。它能保证当原始数据变化时,索引能够极其精准且快速地定位并更新。它还会多占用大约 10% 的索引内存,但能显著提升写操作的吞吐量并保证一致性。如果你在旧版本文档中看到 NO_BACKLINKS,那是用来关闭它的。在生产环境中,请保持其默认开启状态。
生产环境下的 redis.conf 配置示例
1 | ################## REDISEARCH CONFIG ################## |
生产环境的 “避坑” 建议
- ① 严控内存淘汰策略 (
maxmemory-policy)。在启用 RediSearch 后,严禁使用 allkeys-lru 或 allkeys-random。原因是RediSearch 的索引元数据是存储在内存中的非 Key 数据。如果 Redis 触发了全局淘汰,删除了某个 Hash 键,但索引层可能出现短暂不同步,或者因为频繁删除导致索引碎片化严重。建议使用 volatile-lru 或 noeviction,并配合监控严格控制 maxmemory。 - ② 禁用或慎用 KEEPEVECTED。默认情况下,如果文档被删除,索引会自动清理。但在极高频更新的场景下,可以关注 GC_POLICY 参数。生产环境建议使用默认的 FORK 模式(后台清理),避免在主线程中执行耗时的垃圾回收。
- ③ 监控命令:
FT.INFO。不要只看 Redis 的INFO命令。在生产中,你需要定期运行 “FT.INFO myIdx”。重点关注:- inverted_sz_mb:倒排索引占用的内存大小。
- num_docs:索引中的文档总数。
- hash_indexing_failures:如果这个值在增加,说明你的数据格式可能不符合 SCHEMA 定义。
- 针对特有的向量搜索 (Vector Search) 建议:请注意向量索引是内存密集型的。
BACKLINK:默认开启。它会维护索引到 Key 的反向链接,虽然多占一点内存,但在生产中对于保证数据一致性至关重要,不要关闭。
RedisJSON 的编译安装
上述安装 RediSearch 的时候,我们已经踩过坑了,所以环境基本没问题。所以这里我们只记录下载源码和编译集成的过程。
关键安装步骤
下载源码
1 | git clone https://github.com/RedisJSON/RedisJSON.git -b v.8.2.0 |
编译执行
这里提供两种编译方式。推荐方式 B,因为它可以绕过复杂的 Makefile 逻辑,直接通过 Rust 的包管理器进行构建,成功率更高。
方式 A:通过 Makefile 编译 (封装方式)
1 | # 必须使用 RELEASE=1,否则生成的 .so 文件未经过优化,体积巨大且性能极差 |
方式 B:通过 Cargo 直接编译 (原生方式,推荐)
1 | # 直接调用 Rust 编译器 |
产物部署与安装
编译完成后,需要手动将模块移动到 Redis 的加载目录。
1 | # 1. 创建模块存放目录 |
RedisJSON 生产环境参数配置建议
相比于 RediSearch,RedisJSON 的配置参数较少,因为它主要依赖 Rust 的内存管理。但在生产环境中,由于它涉及复杂的 JSON 解析和路径查找,合理的参数设置能有效防止大对象导致的 Redis 阻塞。配置同样通过 redis.conf 中的 loadmodule 传递:
1 | loadmodule /etc/redis/modules/rejson.so [参数名] [参数值] ... |
核心生产参数:
- RETENTION_POLICY:默认值 0(不删除),保留策略。在极少数版本中用于控制旧版本文档的留存。生产环境通常保持默认。
- MAX_NESTING_LEVEL:建议值 100。最大嵌套深度。防止递归解析极深的恶意 JSON(例如嵌套 1000 层的数组)导致栈溢出。100 层足以满足 99% 的业务需求。
- MAX_QUERY_COMPLEXITY:建议值 1000。查询复杂度上限。限制单次 JSON 路径查找(如模糊路径
..*)所能扫描的最大节点数,防止 CPU 耗尽。
生产环境下的 redis.conf 配置示例
1 | ################## REDIS MODULES ################## |
生产环境下的内存与安全建议
- ① 严控大 JSON 对象:Redis 是单线程模型,处理一个 100MB 的 JSON 文件的解析(JSON.SET/GET)会导致 Redis 产生严重的毫秒甚至秒级卡顿。在应用层控制单个 JSON 文档的大小,通常建议不超过 1MB。如果必须存储大文档,请将其拆分为多个 Key。
- ② 选择正确的持久化策略 (AOF vs RDB):RedisJSON 的数据存储在内存中,在持久化时:
- RDB:由于 RedisJSON 优化了存储格式,RDB 的生成速度较快,但要注意 Fork 时的内存翻倍。
- AOF:频繁更新 JSON 的某个子字段会产生大量的 AOF 写操作。确保开启
auto-aof-rewrite-percentage 100,防止 AOF 文件由于细碎的 JSON 指令(如JSON.STRAPPEND)无限膨胀。
- ③ RedisJSON 和 RediSearch 的联动参数 BACKLINK:在 Redis 8+ 中这两者的联动非常频繁,当 JSON 文档更新时,它会通知 RediSearch 增量更新。在 loadmodule rejson.so 时不需要额外开启此项,但要确保两个模块的版本完全一致。
生产监控关键指标
在生产中,请务必关注 INFO modules 和数据本身:
- 内存占用对比: 你可以对比同一份数据在 HASH 和 JSON 下的占用。通常 JSON 格式因为需要维护树状结构,会多出约 20%-30% 的内存开销,这是正常的 “空间换功能”。
- 慢查询日志 (Slowlog): 监控 SLOWLOG GET。如果发现 JSON.GET 或 JSON.SET 频繁出现在慢日志中,说明你的 JSON 文档过大或 JSONPath 表达式(如带有过滤器的查询
$[?(@.price > 100)])太复杂。
1 | > INFO modules |