Docker 基础(一)- 镜像、容器、仓库、数据卷以及常用命令
Build, ship and run any App, Anywhere.
一次镜像,处处运行。从搬家到搬楼。
为什么需要 docker
传统上认为,如那件开发测试完成之后,所产生的成果即是程序或者是能够执行的二进制字节码等。而为了让这些程序能够顺利执行,开发团队也要准备完整的部署文件,让运维团队得以部署应用程序,开发需要清楚地告诉部署团队,用的全部的部署文件以及所有的软件环境。不过即便如此,仍然会常常发生部署失效的问题。Docker的出现使得它得以打破 “程序即应用” 的观念。通过 “镜像” images 将作业系统核心除外,运作应用程序所需要的系统环境,由下而上打包,达到应用的跨平台间的无缝接轨运作。
Docker 官网、Docker 镜像仓库、Docker 文档
场景一:环境配置与在我电脑上明明是好的
- Before(没有 Docker 之前):新员工入职或者搭建新测试环境时,需要手动安装 Java、MySQL、Redis、Nginx。可能因为环境的差异,有时候你就会奇怪,这代码在我电脑上明明是好的啊,怎么到你这就不行了? 配置环境动辄耗时几天。
- After(有了 Docker 之后):开发人员把程序和它所依赖的所有环境(JDK、系统库、配置文件)整体打包成一个镜像(Image)。无论是谁的电脑,无论是 Windows、Mac 还是 Linux 服务器,只需要执行一行命令 docker run my-app。软件在任何地方都能以完全一致的方式运行。
场景二:微服务架构下的资源开销与隔离
- Before(没有 Docker 之前):为了防止多个应用互相抢占资源、或者发生版本冲突(比如 A 应用要用 Python 2,B 应用要用 Python 3),传统的做法是使用虚拟机(VM,如 VMware、VirtualBox)。每个虚拟机都必须包含一个完整的操作系统(Gues OS),动辄几个 GB 甚至几十个 GB。电脑或服务器的内存瞬间被虚拟机吃光,启动一个虚拟机要好几分钟,白白浪费了大量的 CPU 和内存资源。
- After(有了 Docker 之后):Docker 采用的是容器(Container)技术,它不需要虚拟出整个操作系统,而是共享宿主机的操作系统内核。每个容器都是一个轻量级的独立沙盒,大小通常只有几十兆(MB)。在一台服务器上,以前只能跑 3 个虚拟机,现在可以轻松跑 30 个 Docker 容器,启动时间更是达到了毫秒级。服务器硬件成本直接砍掉 70%。
场景三:大促期间的高并发弹性扩容
- Before(没有 Docker 之前):双十一大促或者突发流量爆棚,现有的 2 台服务器快扛不住了,需要紧急扩容 10 台服务器。运维工程师连滚带爬地去申请新机器,然后开始机械地重复:装系统、装依赖、同步代码、改配置文件、挂载域名…,等这 10 台服务器手工配置好,流量高峰早就过去了,用户全部流失,服务器还配错了两个参数。
- After(有了 Docker 之后):配合容器编排工具(如 K8s),实现真正的自动化弹性伸缩。系统监测到 CPU 达到 80% 阈值,自动触发扩容脚本。Docker 镜像在几秒钟内瞬间“克隆”出 10 个一模一样的容器投入战斗,流量过去后又自动销毁,整个过程甚至不需要人工干预。
容器和虚拟机的对比
虚拟机(VM)是硬件级别的虚拟化,它虚拟的是整个操作系统; 而 Docker 容器是操作系统级别的虚拟化,它虚拟的是进程。我们可以看它们的架构对比:
- 虚拟机(VM):在物理机上有一层 Hypervisor(虚拟机监视器),它在硬件之上去模拟出 CPU、内存、硬盘,并在其上安装一个完整的客户操作系统(Guest OS)。你的应用是运行在这个独立的、沉重的 OS 之上的。
- Docker 容器:没有 Hypervisor,也不需要 Guest OS。它直接利用了宿主机(Host OS)的内核,通过 Linux 的 Namespace(名称空间)实现资源隔离(比如让容器拥有独立的 IP、进程 ID、文件系统,感觉自己独占了系统),通过 Cgroups(控制组)实现资源限制(防止某个容器疯狂吃满宿主机的 CPU 或内存,导致其他应用卡死)。对宿主机而言,一个容器本质上就是一个受限制的普通进程。

在实际的企业级微服务架构中,它们并不是非此即彼的竞争关系,而是互补的合作关系。现在大厂的流行架构是:将 Docker 容器跑在虚拟机上。
- 云厂商/基础设施层:利用虚拟机来做第一层物理安全隔离。比如租用阿里云、腾讯云的 ECS 虚拟机,保证各租户之间、各核心业务之间的绝对安全。
- 应用研发/部署层:在这些虚拟机内部部署 Docker(配合 K8s 编排)。利用容器的轻量级和高并发性,来实现微服务的极速启动、持续集成(CI/CD)以及大促期间的自动弹性扩容。
这样既享受了虚拟机的高隔离安全性,又享受了 Docker 的高敏捷低开销。
Docker 三要素-镜像、容器、仓库
核心定义
Docker 的三件套构成了容器技术的整个生命周期。我们可以用面向对象编程或者集装箱运输这两个经典比喻,把它们的关系说得非常透彻:
- ① 镜像 (Image) —— “只读的类 / 运送的货物”
- 镜像是一个特殊的文件系统。它打包了应用程序运行所需的所有一切——包括代码、运行环境、系统库、配置文件以及环境变量。镜像是只读(Read-Only)的,分层存储。
- 它就像是面向对象编程里的 “类(Class)”,或者一张“建筑设计图纸”。在集装箱流派里,它就是那个在工厂里刚打包好、还没装车的 “标准集装箱”。
- ② 容器 (Container) —— “运行的实例 / 移动的车辆”
- 容器是镜像运行时的实体。容器可以被创建、启动、停止、删除。容器的本质是宿主机上的一个独立进程,它在镜像的只读层之上,加了一个可写层(Writable Layer)。
- 它就像是根据 “类” 通过 new 出来的一个个 “对象(Object)”,或者根据图纸盖出来的 “真实房子”。多个容器之间相互隔离,你在容器里的读写操作只会影响可写层,绝不会破坏底层的镜像。
- 从镜像容器的角度来看,可以把容器看作是一个简易版的linux环境(包括root用户权限、进程空间、用户空间和网络空间等)以及运行在其中的应用程序。
- ③ 仓库 (Registry / Repository) —— “中央代码托管所 / 货运码头”
- 仓库是集中存放镜像文件的场所。一个配置了特定域名的服务器叫 Registry(注册中心,如 Docker Hub),而 Registry 里面包含多个 Repository(镜像仓库,通常一个 Repository 对应一个软件,如 MySQL 仓库、Redis 仓库)。
- 它就像是代码届的 GitHub / Maven 统一中央仓库,或者港口边巨大的“集装箱停放码头”。开发者把做好的镜像推送到这里托管,其他人可以随时拉取。
- 仓库分为公开仓库和私有仓库两种形式。最大的公开仓是 Docker Hub(https://hub.docker.com),上面存放了大量的镜像可供用户下载。国内的公开仓库包括阿里云、网易云等。
三者的核心纽带
在底层,Docker 镜像是由多层(Layers)只读文件系统叠加而成的(联合文件系统 UnionFS)。当我们执行 docker run 启动一个容器时,Docker 只是在这一堆只读的镜像层之上,挂载了一个极薄的可写层(也叫容器层)。
- 当容器内的程序修改文件时,它会触发 Copy-on-Write(写时复制)机制:把镜像层的文件复制到可写层再修改。
- 这种设计意味着,哪怕你启动 100 个容器,它们也共享同一份底层的镜像数据,内存占用极低,这也是容器比虚拟机轻量快捷的根本原因。
在项目中的实际协同
在实际项目开发中,这三件套是这样闭环协同工作的:
- Build(构建镜像):Java 开发工程师编写好代码后,通过编写 Dockerfile,执行
docker build命令,把 Spring Boot 应用和 JDK 环境打包成一个镜像(Image)。 - Push(推送仓库):通过
docker push命令,将这个镜像推送到公司的私有仓库(Registry)(如 Harbor)中托管。 - Pull & Run(拉取并运行成容器):运维工程师或者 K8s 自动化部署脚本,在生产服务器上通过
docker pull从仓库拉取该镜像,并执行docker run。镜像在内存中被实例化,变成一个提供线上服务的容器(Container)。
这就是 Docker 三件套通过构建、交付、运行实现代码到处运行的完整过程。
Docker 的工作原理
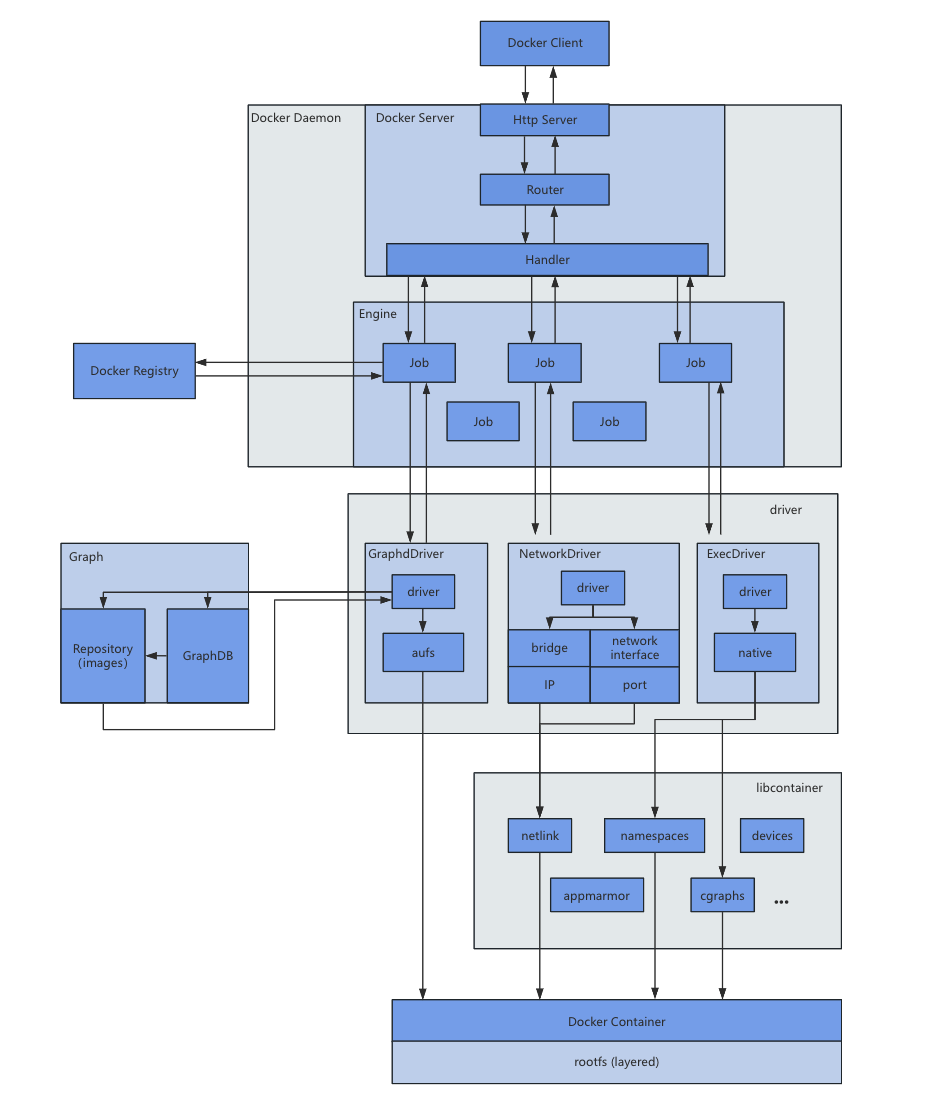
Docker 是一个 CS 结构的系统,后端是一个松耦合架构,众多模块各司其职。Docker 守护进程运行在主机上,然后通过 Socket 连接从客户端访问,守护进程从客户端接受命令(比如 docker build)并 管理运行在主机上的容器。容器是一个运行时的环境,就类似于前面说到的 “集装箱”。
Docker 运行的基本流程为:
- 用户使用 Docker Client 与 Docker Daemon 建立通信,并发送请求给后者。
- Docker Daemon 作为 Docker 架构中的主体部分,首先提供 Docker Server 的功能使其可以接受 Docker Client 的请求。
- Docker Engine 执行 Docker 内部的一系列工作,每一项工作都是以一个 Job 的形式存在。
- Job 运行的过程中,当需要容器镜像的时候,则从 Docker Registry 中下载镜像,并通过镜像管理驱动 Graph Driver 将下载的镜像以 Graph 的形式存储。
- 当需要为 Docker 创建网络环境时,通过网络管理驱动 Network Driver 创建并配置 Docker 容器的网络环境。
- 当需要限制 Docker 容器的运行资源或这行用户指令等操作的时候,则通过 Execute Driver 来完成。
- libcontainer 是一项独立的容器管理包,Network driver 以及 Exec driver 都是通过 libcontainer 来实现具体的对容器的操作。
Docker Engine 的安装和卸载
以 centos10 为例进行演示(请参考官网的安装卸载说明 Install Docker Engine on CentOS)。这里想说明的是,如果官网存在下载问题,可以切换为国内阿里或清华的 Docker 镜像源;2. 将源路径中的版本强制指定为 9(因为 10 完全兼容 9 的包)。
第一步:删除旧的、失效的官方软件源文件。为了防止旧的官方源继续干扰 dnf,先把它删掉:
1 | sudo rm -f /etc/yum.repos.d/docker-ce.repo |
第二步:下载国内阿里源并修正 CentOS 10 的路径。由于我们要借用 CentOS 9 的 Docker 稳定包,我们需要下载阿里源,并用 sed 命令把里面的系统版本变量 $releasever(在你的系统里是 10)强行替换为 9。执行以下组合命令:
1 | # 1. 下载阿里云的 Docker CE 软件源 |
第三步:清除缓存并重新安装。现在,清理掉之前失败的残存缓存,重新生成索引并安装:
1 | # 清理 dnf 缓存 |
安装完成后,Docker 默认是没有启动的,执行以下命令启动并设置开机自启:
1 | # 启动 Docker 服务 |
成功安装后,在本地 docker pull 拉取镜像(如 MySQL、Redis)时,由于同样的网络原因可能还会遭遇超时。建议你提前配置好 Docker 镜像加速器(可以使用阿里云容器镜像服务的个人专属加速器,或者国内高校的公开加速器),修改 /etc/docker/daemon.json 文件即可,它是 Linux 下 Docker 的核心配置文件。我们直接用一条组合命令,把国内目前可用的加速器地址写入该文件(如果文件不存在会自动创建):
1 | sudo mkdir -p /etc/docker |
公开的加速器偶尔会因为流量过大而失效。如果你有阿里云账号,建议登录【阿里云控制台 -> 容器镜像服务 ACR -> 镜像工具 -> 镜像加速器】,那里会有一个你个人专属的加速器地址(格式类似 https://xxxxxx.mirror.aliyuncs.com)。把那个地址也加到上面的列表里,速度会飞起且极度稳定。注意:国内的 “镜像加速器” 只对 docker pull(拉取)和 docker run(运行)有效,而对 docker search(搜索)无效。 当执行 docker search 时,Docker 引擎固定会去死磕官方的索引服务器 index.docker.io,而这个地址目前在国内是被彻底阻断的,所以依然会报 i/o timeout。推荐直接在网页端搜索 https://hub.docker.com/。
现在,你可以重新验证你的第一个 Docker 容器了:
1 | # docker run hello-world |
如果运行还遇到问题,可以执行以下命令:
1 | docker info |
Docker 的常用命令
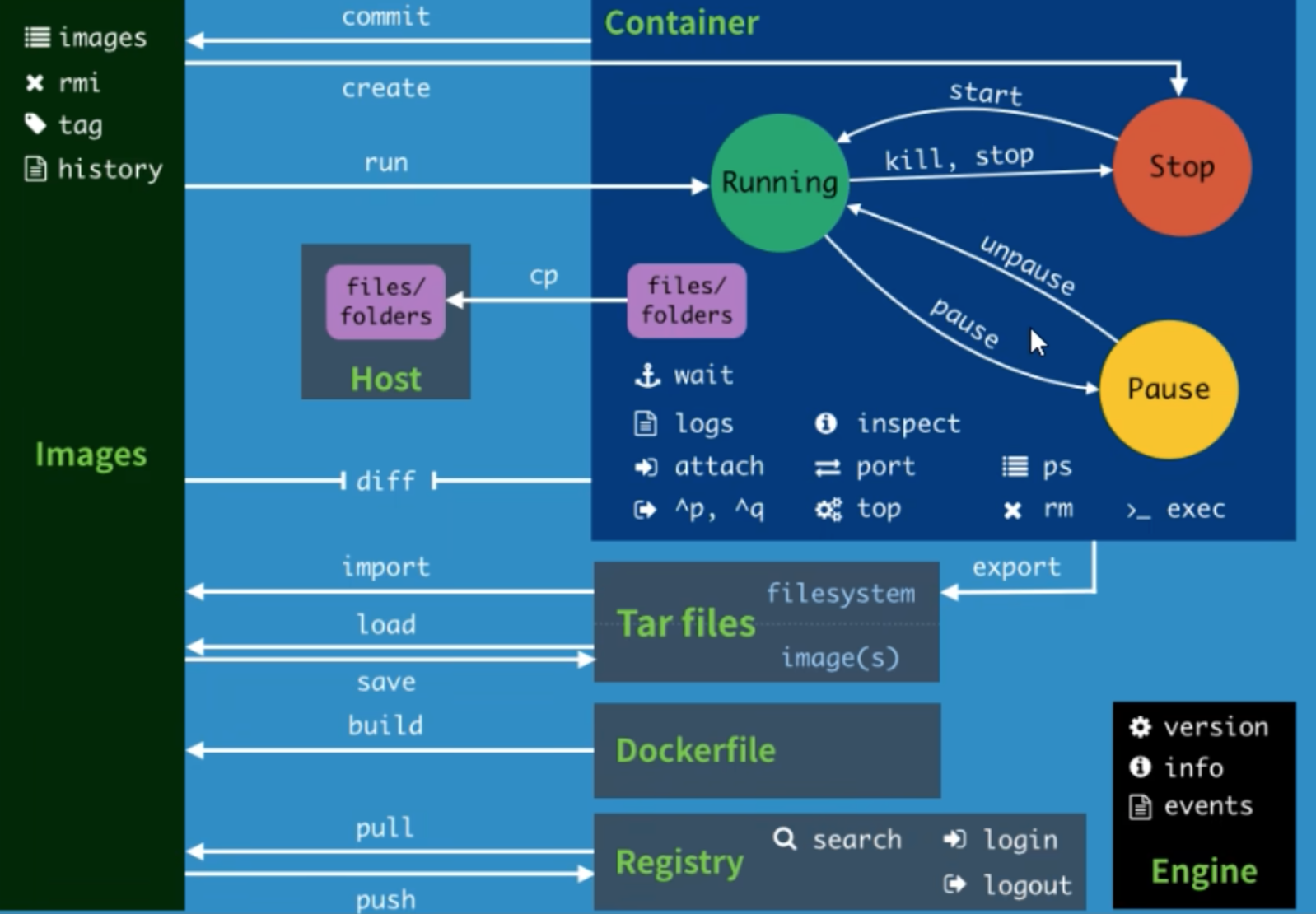
帮助启动类命令:
1 | # 启动 docker |
镜像命令:
1 | # 列出本机上的镜像 |
容器命令:
1 | # 新建容器 |
退出容器:
1 | # 两种退出方式 |
备份:
1 | # 文件或文件夹备份(文件或者文件夹中的全部内容将会被拷贝到宿主机),也可以实现宿主机往docker容器的拷贝 |
系统管理
1 | $ docker system --help |
容器使用的状态监控:
1 | $ docker stats |
镜像的分层
什么是镜像的分层?
Docker 镜像的分层,底层主要依赖于 Linux 的 联合文件系统(UnionFS,Union File System) 技术。它是一种分层、轻量级并且高性能的文件系统。它能把多个不同的只读目录叠加到同一个挂载点上,在外面看起来就像是一个整体的、连续的独立文件系统。
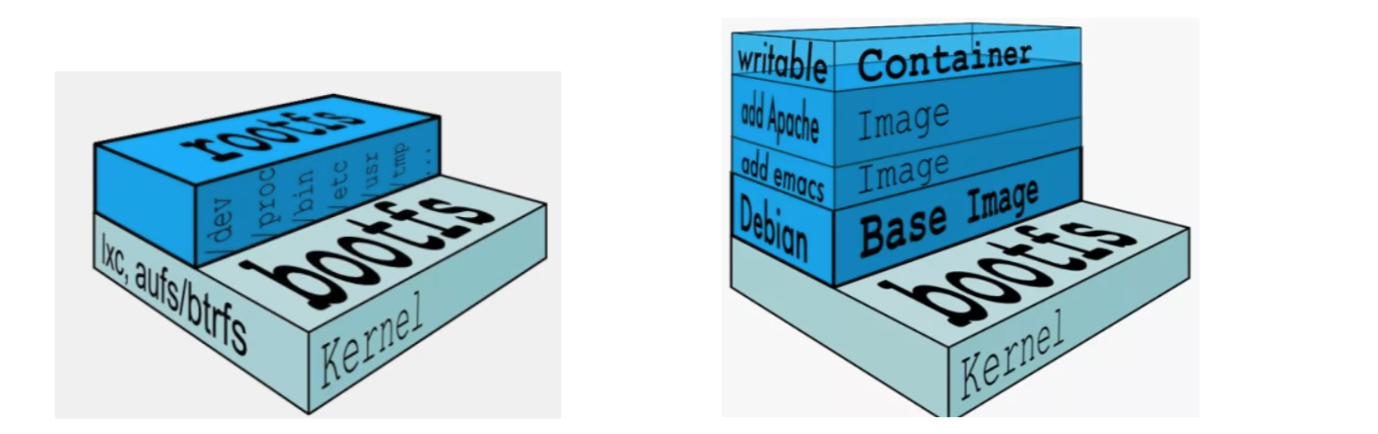
- 最底层:基础层 (Kernel & OS)
- bootfs (引导文件系统):包含系统的 Bootloader 和 Kernel。当容器启动后,bootfs 会被卸载以节约内存,容器会直接复用宿主机的内核。
- rootfs (基础操作系统层/Base Image):比如 ubuntu、centos 或 alpine。它包含了典型 Linux 系统中的 /dev、/proc、/bin、/etc 等标准目录,但不包含内核。对于一个精简的OS,rootfs 可以非常小,只需要包含最基本的命令、工具和程序库就可以,因为底层直接用Host的kernel,自己只需要提供 rootfs 就可以了。由此可见对于不同的 linux 发行版,bootfs 基本上是一致的,rootfs 会有差别,因此不同的发行版可以共用 bootfs。
- 中间层:只读指令层 (Read-Only Layers)——只读镜像层。
- 我们在 Dockerfile 中写的每一条会改变文件系统的指令(如 RUN, COPY, ADD),在构建(docker build)时都会生成一个新的、只读的独立镜像层。
- 核心纽带(写时复制 Copy-on-Write):如果高层想要修改低层的文件,Docker 并不会直接修改低层(因为低层是只读共享的),而是先将该文件复制到高层,然后在高层进行修改并隐藏低层的文件。这种机制被称为 CoW (Copy-on-Write)。
- 最顶层:可写容器层 (Container Writable Layer)
- 当我们执行 docker run 启动容器时,Docker 会在所有只读镜像层的最上方,挂载一个极薄的、可读可写的空层(Container Layer)。
- 容器内部运行期间的所有增删改查(如写应用日志、生成临时文件),全部只会发生在最顶部的可写层。一旦容器被删除,这个可写层也会随之烟消云散,而底层的镜像层永远保持只读、不被污染。
为什么要设计成分层?
- 共享资源,节省空间:如果本地有 10 个 Java 应用镜像,它们都是基于 openjdk:17-alpine 构建的。那么这 10 个镜像在硬盘上只会占用一份 OpenJDK 镜像的实际空间。
- 极速分发,节省带宽:当你在生产环境更新应用,通过 docker pull 拉取最新镜像时,Docker 会自动比对。如果基础层和中间依赖层没有变,它只会拉取最新的那一层应用代码包(通常只有几 MB),实现了秒级部署。
- 高效复用构建缓存:在本地开发构建时,如果没有改动前面的指令,Docker 会直接复用之前的层缓存(Using cache),极大地加快了 CI/CD 流程。
实战原则
了解了 Docker 镜像的分层机制,在实际开发中写 Dockerfile 时,应刻意遵循以下几个优化原则:
- 原则一:将高频变动的层往后放。比如在写 Java 镜像的 Dockerfile 时,应该先 RUN mkdir、先安装环境依赖(变动低频),最后再执行 COPY app.jar(变动极高频)。这样可以最大化地利用构建缓存(Cache)。
- 原则二:合并 RUN 指令以减少层数。
- 反面教材:连续写好几行 RUN apt-get update、RUN apt-get install、RUN rm -rf。这会无端生成 3 个镜像层,哪怕你在最后一行删除了垃圾文件,前两层里依然死死保留着那些垃圾文件的体积。
- 正确姿势:用
&&符号将它们串联成一条命令,只生成一个镜像层,并在该层结束前清理掉缓存:RUN apt-get update && apt-get install -y git && rm -rf /var/lib/apt/lists/*
- 原则三:采用多阶段构建 (Multi-Stage Builds)。例如第一阶段利用 Maven 镜像去编译打包(会产生几百 MB 依赖残渣),第二阶段只把打包好的 jar 包 COPY 到一个纯净的、只有几十兆的 alpine-jre 基础镜像中。最终产出的生产镜像中,完全不包含任何编译期间的臃肿历史层。
实际案例
Docker 中的镜像分层,支持通过扩展现有的镜像,创建新的镜像。类似 Java 继承于一个 Base 基础类,自己再按需扩展。新镜像是从 Base 镜像一层一层叠加而成的。每安装一个软件,就在现有的镜像基础上增加一层 。
在原始的 ubuntu 的基础上,做一个包含 vim 的 ubuntu 镜像:
1 | # 1 |
将新做的镜像发布到阿里云:
1 | # 登录阿里云,选择 “容器镜像服务”,创建阿里云个人版容器镜像托管服务 |
从阿里云拉取我们上传的镜像到本地:
1 | $ docker images |
Docker 私有库
什么是私有库
私有库是建立在企业内部网络(或云厂商私有网络)中的镜像存储中心。它提供与 Docker Hub 类似的镜像推拉(Push/Pull)功能,但增加了更严格的权限控制、审计和网络隔离。
私有库的主流选型
- 官方 Registry:Docker 官方提供的极简版私有库(本质是个镜像)。没有 UI 界面,没有用户权限管理。适用于个人测试、微型团队、或作为 K8s 集群底层组件。
- Harbor(最主流):虚拟机/容器时代由 VMware 开源的企业级 Registry。支持图形化界面(UI)、RBAC 权限控制、镜像复制、漏洞扫描、操作审计。它是中大型企业生产环境的首选方案。
- 云厂商托管(ACR/SWR):如阿里云的 ACR、腾讯云的 TCR。无需自己维护服务器,直接付费使用。团队整体业务已全面上云的场景。
用官方 Registry 搭建私有库
官方的 Registry 也是一个 Docker 镜像,直接一行命令即可在后台启动:
1 | # -p 5000:5000:私有库默认暴露 5000 端口。 |
现在我们把本地的一个镜像(比如 hello-world)推送到这个刚建好的私有库里。
① 为本地镜像 “打标签(Tag)”。Docker 规定,要推送到私有库的镜像,其名字必须带上私有库的 IP 和端口作为前缀,否则 Docker 会默认推送到官方 Hub。
1 | # 格式:docker tag 原镜像名:标签 私有库IP:端口/新镜像名:标签 |
② 推送(Push)到私有库
1 | docker push 127.0.0.1:5000/my-hello:1.0 |
③ 验证私有库中有哪些镜像。你可以通过 Registry 提供的内置 RESTful API 来查看里面的镜像列表:
1 | curl -X GET http://127.0.0.1:5000/v2/_catalog |
上面我们用 127.0.0.1 测试一切正常,但如果另一台服务器(比如客户端 B,IP 为 192.168.1.100)想要拉取这台私有库服务器(IP 为 192.168.1.50)的镜像,执行 docker push 192.168.1.50:5000/my-hello:1.0 时,会直接报如下致命错误:http: server gave HTTP response to HTTPS client。这需要在需要拉取或推送镜像的客户端服务器上,修改 Docker 核心配置文件 /etc/docker/daemon.json,告诉 Docker 允许信任这个 HTTP 的私有库:
1 | $ vim /etc/docker/daemon.json |
此时,局域网内的其他服务器就可以愉快地自由 pull 和 push 内部镜像了。
实际生产环境一般使用的是 Harbor。因为官方的 Registry 虽然轻量,但它致命的缺点是没有任何权限控制,只要知道了 IP 和端口,任何人都能任意推拉甚至覆盖镜像,这在生产中是极其危险的。
Harbor 在官方 Registry 的核心上包裹了一层企业级功能。它提供了高颜值的 Web UI 界面。我们可以在上面为开发、测试、运维建立不同的项目组,并通过 RBAC(基于角色的权限控制)精确分配谁能看、谁能推码。此外,Harbor 还集成了 Trivy 等漏洞扫描工具,镜像推上去会自动扫描漏洞,不安全的镜像直接拦截部署。同时它还支持多机房镜像自动同步复制,非常适合我们做微服务多机房容灾部署。
容器的数据卷
为什么要引入数据卷
要理解数据卷,首先必须理解容器的临时性(Episodic/Ephemeral)特征。默认情况下,容器内产生的所有数据(比如 MySQL 的 ibdata1 文件、应用的 Log 日志)都是保存在最顶层的‘可写层’的。这就带来了三大致命痛点:
- 数据随容器消亡:一旦执行 docker rm 删除了容器,里面的数据会瞬间灰飞烟灭。
- 性能较差:可写层底层的写时复制(Copy-on-Write)机制涉及到复杂的文件系统联合挂载,读写性能(I/O)远不如宿主机原生文件系统。
- 数据隔离,无法共享:两个容器之间想要实时共享一套配置文件或静态资源非常困难。
为了解决这些问题,Docker 引入了数据卷(Volumes)机制——将宿主机的目录或文件,直接挂载到容器的文件系统中,实现数据的持久化和独立生命周期。
数据卷的两大主力流派
容器数据卷 (Volumes):
- 机制:由 Docker 引擎完全管理的挂载方式。Docker 会在宿主机的专属安全目录(Linux 下通常是
/var/lib/docker/volumes/)下创建一块区域留给该容器,数据被写在了宿主机由 Docker 引擎专属管理的特定安全目录下。这种方式的可移植性相对较高,跟宿主机系统路径解耦,K8s/Docker Swarm 友好。适用于数据库持久化(MySQL, Redis)、公共日志存储。 - 细分:
- 匿名卷:不指定宿主机名字(如 -v /usr/share/nginx/html),Docker 自动生成一串哈希值作为目录名。不好维护,生产很少用。
- 具名卷(推荐):明确给它起个名字,如 -v my_mysql_data:/var/lib/mysql,数据被写在宿主机的 /var/lib/docker/volumes/my_mysql_data/_data 这个路径下,当容器里的 MySQL 往 /var/lib/mysql 写入一条数据时,底层通过 Linux 挂载机制,直接穿透容器,实时写到了宿主机的上述路径中。在第一次执行命令时,如果宿主机的 my_mysql_data 卷里是空的,而 MySQL 镜像的 /var/lib/mysql 里本来就有系统自带的初始文件,Docker 也会聪明地把容器内的这些初始文件先复制到宿主机的这个目录下。随后两边合二为一,指向同一个物理位置。
- 核心特点:“容器管内,Docker 管外”。你不需要关心宿主机的真实路径,Docker 负责其安全和生命周期,即使容器删了,这块数据依然完好无损。
绑定挂载 (Bind Mounts):
- 机制:直接将宿主机上任意明确的绝对路径挂载到容器内(如 -v /home/project/conf:/etc/nginx/conf)。这种方式的可移植性相对较低,换一台机器如果不存在该绝对路径,容器会报错启动失败。适用于配置文件挂载、本地开发代码热加载。
- 核心特点:“极度自由,双向绑定”。宿主机和容器内对该目录的修改会互相同步。非常适合把代码或配置文件挂载进容器,在宿主机上热修改、热部署。即使容器挂掉或者删除,数据依然存在于宿主机,下次容器开启,数据更新也会自动加载到容器中。
- 霸道篡改特性:与具名卷不同,绑定挂载非常 “霸道”。当你把宿主机的 /home/project/conf 挂载到容器的 /etc/nginx/conf 时,无论容器里原本该目录下有什么文件,都会被瞬间隐藏。如果你宿主机的 /home/project/conf 是空的,那容器进去后看到的 /etc/nginx/conf 也是空的(即使 Nginx 镜像里本来有默认配置)。
注意:无论哪种挂载方式,数据在宿主机上都只写了一份,绝不存在写两份占双倍空间的情况。Docker 的数据卷挂载,本质上利用的是 Linux 内核的 mount –bind(绑定挂载)技术。它就像是在 Linux 系统里创建了一个硬链接或快捷方式,让容器内的路径和宿主机的路径共同指向了硬盘上的同一块物理区域。
项目中的最佳实践
规范一:生产环境数据库、中间件一律强制挂载(具名卷)
绝不允许任何有状态(Stateful)的容器“裸奔”。
1 | # 以运行 MySQL 为例,必须通过具名卷 my_sql_data 将数据持久化 |
规范二:只读挂载保护核心配置 (ro)
在微服务部署时,如果只是想让容器读取宿主机的配置文件(如 Nginx 配置),为了防止容器内的黑客攻击或程序 Bug 篡改宿主机的配置,我们会加上 :ro(Read-Only) 权限限制:
1 | # 加上 :ro 后,容器内部对该配置只有只读权限,强行修改会报 Permission denied |
规范三:利用 –volumes-from 实现容器间数据继承与备份
在做日志收集(如 ELK / Filebeat)时,我们会让日志收集容器通过 –volumes-from 继承业务容器的数据卷,实现不侵入业务代码的分布式日志采集,这也是微服务中非常经典的 Sidecar(边车)设计模式。容器2继承自容器1 的数据卷配置,即使在容器1挂了,也不会影响到容器2。