哈希查找法
哈希查找简介
如果说二分查找靠的是层层 “精密的筛选”,那么哈希查找就是 “瞬间移动”。它在理想情况下的时间复杂度是惊人的 $O(1)$。
核心本质:从比较到计算
普通的查找算法,本质都是比较:A 是否等于 B?如果不等,是大还是小?
而哈希查找彻底抛弃了比较,它的核心逻辑是:通过一个函数,直接把 “值” 变成 “地址”。
- 二分查找:在一排储物柜里,按编号一半一半地找。
- 哈希查找:你手里有一张纸条(哈希函数),上面写着:”柜子编号 = 你的姓名拼音首字母”。你只需看一眼名字,就直奔那个柜子,根本不需要看别的柜子一眼。
哈希查找的三大支柱
① 哈希函数 (Hash Function):
我们需要一个数学公式,把任何输入(数字、字符串、甚至对象)转换成一个固定的数组下标。 最简单的公式是取模法:index = target % arraySize。
② 哈希表 (Hash Table)
本质上是一个数组。哈希函数计算出来的索引,就是数据在这个数组里的存储位置。
③ 哈希冲突 (Hash Collision) —— 最关键的问题
如果 “张三” 计算出的位置是 5,”李四” 计算出的位置也是 5,该怎么办?我们这里使用最简洁直观的拉链法:在位置 5 挂一个链表,冲突的人都排在链表里。
简单哈希查找代码
MyHashMap 的存取过程演示
已加载初始化数据。
核心代码:
1 | /** |
为什么它是终极武器
我们来看它和二分查找的比较:
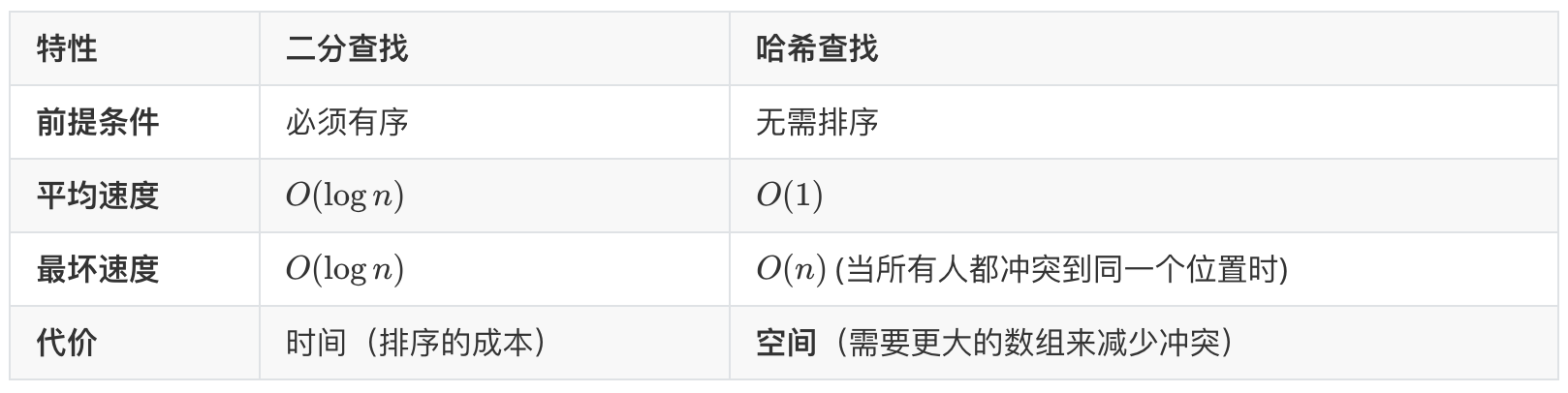
哈希查找虽然快到极致,但它也是有代价的,那就是它牺牲了 “顺序性”。
- 如果你问哈希表:“告诉我这里面最小的数是谁?” 它会一脸懵逼,因为它根本不记得谁大谁小。
如果你问:“帮我找 20 到 50 之间的所有数?” 它也无能为力。
这就是 HashMap、 TreeSet 能够快速定位的核心原理,牺牲数据的顺序性,把
空间换时间这件事做到了极致!