高级排序
希尔排序
排序原理:
- 选定一个增长量 h,按照增长量 h 作为数据分组的依据,对数据进行分组;
- 对分好组的每一组数据完成插入排序;
- 减小增长量,最小减为 1,重复第二步操作。
希尔排序是 O(n^2) 向 O(nlogn) 进化的分水岭。它的复杂度并不是严格的 $O(n \log_2 n)$,而是介于 $O(n \log^2 n)$ 到 $O(n^{1.5})$ 之间,具体取决于你选择的步长序列(h 序列)。但在通俗理解上,我们确实可以说它达到了类似 $O(n \log n)$ 级别的效率。它实际上是插入排序的改进版(也叫缩小增量排序)。它的巧妙之处在于其打破了 “只能相邻交换” 的禁锢,通过大步长的分组交换,让原本处在末尾的小元素能 “跳跃式” 地回到前面。
希尔排序:Knuth 序列动画演示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
public static void shellSort(int[] array) {
int h = 1;
while (h < array.length / 3) {
h = 3 * h + 1;
}
while (h >= 1) {
for (int i = h; i < array.length; i++) {
for (int j = i; j >= h && array[j] < array[j - h]; j -= h) {
swap(array, j, j - h);
}
}
h /= 3;
}
}
|
普通归并排序
普通归并排序交互演示
观察每次合并后,数据必须 “原路返回” 到原数组的额外动作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
public static void mergeSort(Comparable[] array) {
Comparable[] auxArray = new Comparable[array.length];
mergeSort(array, auxArray, 0, array.length-1);
}
private static void mergeSort(Comparable[] array, Comparable[] auxArray, int low, int high) {
if (low >= high) {
return;
}
int middle = low + (high-low)/2;
mergeSort(array, auxArray, low, middle);
mergeSort(array, auxArray, middle+1, high);
merge(array, auxArray, low, middle, high);
}
private static void merge(Comparable[] array, Comparable[] auxArray, int low, int middle, int high) {
int index = low;
int p1 = low;
int p2 = middle + 1;
while (p1<=middle && p2<=high) {
if (array[p1].compareTo(array[p2]) < 0) {
auxArray[index++] = array[p1++];
} else {
auxArray[index++] = array[p2++];
}
}
while (p1<=middle) {
auxArray[index++] = array[p1++];
}
while (p2<=high) {
auxArray[index++] = array[p2++];
}
for (int i = low; i <= high; i++) {
array[i] = auxArray[i];
}
}
|
交替归并排序
由于归并排序是一种稳定排序,算法时间复杂度也非常好,所以在开发实践中这种排序算法非常重要,有必要对其进行一定的优化。优化点:
- 只分配一次空间:在递归开始前,只在堆内存中开辟一块与原数组等长的
aux 辅助空间,所有递归层级共享这一块内存(如果在递归的过程中频繁开辟空间,这会增加内存的碎片化和GC清理负担)。
- 交替归并:这是最精妙的优化。通过在递归层级中交替变换 “源数组” 和 “目标数组” 的角色,彻底消除将结果从辅助数组拷贝回原数组的操作,可减少50%的无效数组搬运。
- 插入排序阈值:小规模使用插入排序,消除递归开销,加快执行速度。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| public static void mergeSort(int[] array) {
int[] auxArray = array.clone();
mergeSort(auxArray, array, 0, array.length - 1);
}
private static void mergeSort(int[] src, int[] dest, int low, int high) {
if (low >= high) {
return;
}
if (high - low < 16) {
insertSort(dest, low, high);
return;
}
int middle = low + (high - low) / 2;
mergeSort(dest, src, low, middle);
mergeSort(dest, src, middle + 1, high);
merge(src, dest, low, middle, high);
}
private static void merge(int[] src, int[] dest, int low, int middle, int high) {
int p1 = low;
int p2 = middle + 1;
for (int i = low; i <= high; i++) {
if (p1 > middle) {
dest[i] = src[p2++];
} else if (p2 > high) {
dest[i] = src[p1++];
} else if (src[p1] < src[p2]) {
dest[i] = src[p1++];
} else {
dest[i] = src[p2++];
}
}
}
public static void insertSort(int[] array, int low, int high) {
for (int i = low + 1; i <= high; i++) {
for (int j = i; j > low; j--) {
if (array[j] < array[j - 1]) {
swap(array, j, j - 1);
} else {
break;
}
}
}
}
|
双路快排
快速排序之所以快,是因为它每次切分都把问题规模缩小了一半,而且它的底层操作全是续内存的交换,对 CPU 缓存(Cache)非常友好。这种算法最坏的情况是 $O(n^2)$。如果数组本身就是已经排好序的,比如 {1, 2, 3, 4, 5}。你选 1 作基准,扫描一圈发现它还是在原地,结果你只切分掉了一个元素,剩下的 4 个还要继续递归。这种 “切分不均匀” 会导致递归深度变成 $n$ 层,效率退化成像冒泡排序一样的 $O(n^2)$。这就是为什么在生产环境(如 JDK 源码)中,基准值通常会采用 “三数取中 ”或者随机选取来规避这个问题。
关于快速排序的稳定性,由于它的交换是跨越式的,所以快速排序是不稳定的。比如数组 [5, 3a, 3b, 2, 9],基准值是 5。在扫描和最后与基准值交换的过程中,原本在前面的 3a 可能会和后面的 3b 交换位置,或者基准值直接跳过了相同的元素。这种长距离的 “瞬移” 会破坏数组的稳定性。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
public static void quickSort(Comparable[] array) {
quickSort(array, 0, array.length-1);
}
private static void quickSort(Comparable[] array, int low, int high) {
if (low >= high) {
return;
}
int index = partition(array, low, high);
quickSort(array, low, index-1);
quickSort(array, index+1, high);
}
private static int partition(Comparable[] array, int low, int high) {
swap(array, low, low+(int)(Math.random()*(high-low+1)));
Comparable key = array[low];
int left = low;
int right = high + 1;
while (true) {
while (array[--right].compareTo(key) > 0) {
if (right == low) {
break;
}
}
while (array[++left].compareTo(key) < 0) {
if (left == high) {
break;
}
}
if (left >= right) {
break;
} else {
Comparable tmp = array[left];
array[left] = array[right];
array[right] = tmp;
}
}
Comparable tmp = array[low];
array[low] = array[right];
array[right] = tmp;
return right;
}
|
注意:以上所以必须取 right 而不能取 left,是因为在双指针碰撞停止时,right 指向的是 “小区” 的最后一个元素,而 left 指向的是 “大区” 的第一个元素。
三路快排
如果说标准的双路快排是死板的二分流水线机械工,那么三路快排就是精通 分而治之 的策略大师。它通过将数组切分为 “小于、等于、大于” 三部分,直接跳过了对重复元素的冗余处理,在处理海量重复数据时,效率提升是跨越式的。” Java 底层默认使用的是三路快速排序,三路快排较之于双路快排,大大优化了处理大量重复元素的情况。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
| public static void quickSort(Comparable[] array) {
quickSort(array, 0, array.length-1);
}
private static void quickSort(Comparable[] array, int low, int high) {
if (low >= high) {
return;
}
if (high - low + 1 < 16) {
insertSort(array, low, high);
return;
}
swap(array, low, low+(int)(Math.random()*(high-low+1)));
Comparable key = array[low];
int lt = low;
int gt = high + 1;
int index = low + 1;
while (index < gt) {
if (array[index].compareTo(key) < 0) {
lt++;
swap(array, index, lt);
index++;
} else if (array[index].compareTo(key) > 0) {
gt--;
swap(array, index, gt);
} else {
index++;
}
}
swap(array, low, lt);
quickSort(array, low, lt-1);
quickSort(array, gt, high);
}
public static void insertSort(Comparable[] array, int low, int high) {
for (int i = low+1; i < high+1; i++) {
for (int j = i; j > low; j--) {
if (array[j].compareTo(array[j-1]) < 0) {
swap(array, j, j-1);
} else {
break;
}
}
}
}
|
以下是一个三路快速排序切分环节的过程示意图:
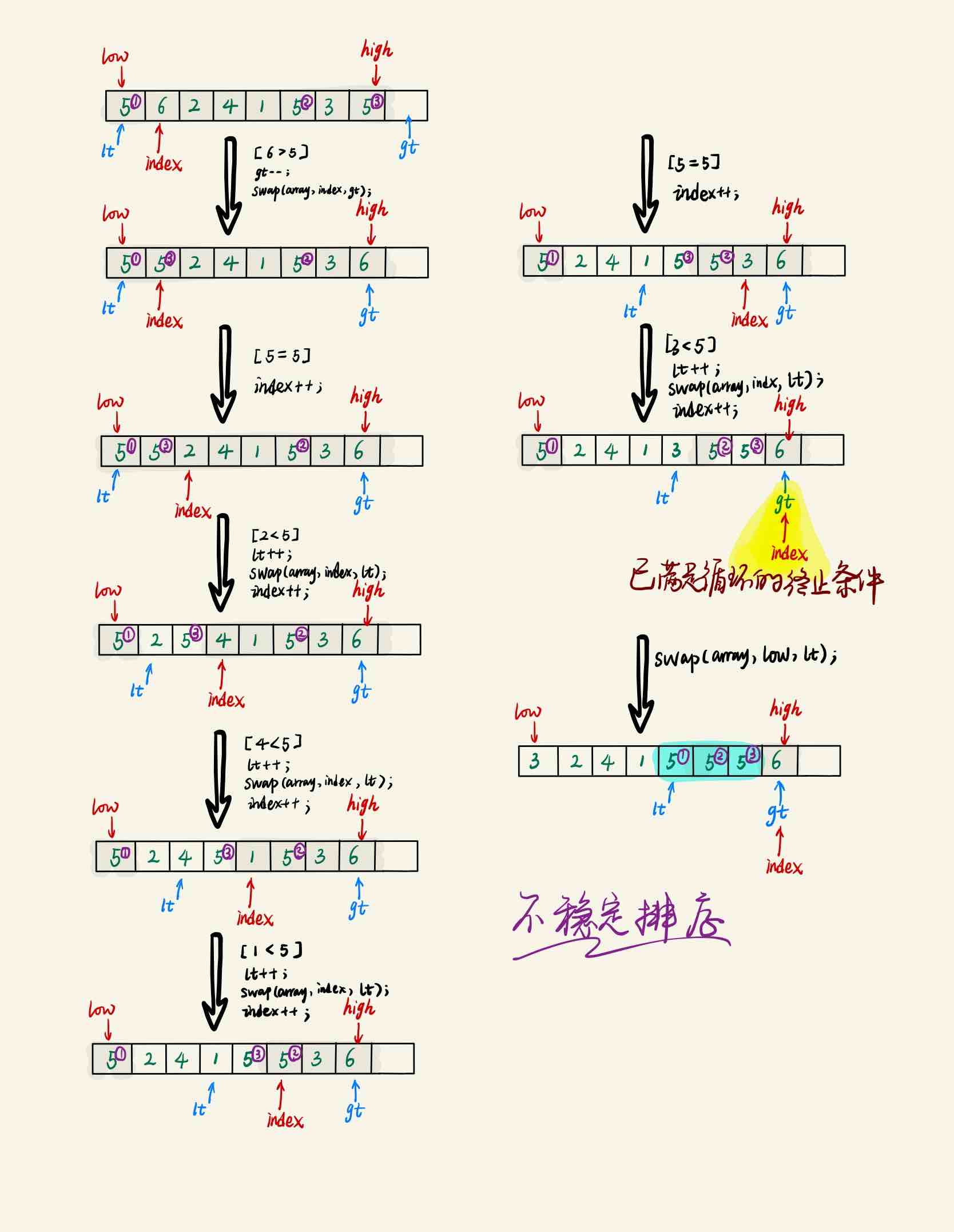
实际怎么用
理论的极限
在讨论世界上最好的排序算法之前,我们需要先看看数学给出的天花板。
比较排序的极限:$\Omega(n \log n)$:
对于绝大多数我们熟悉的排序算法(快排、归并、堆排),它们都属于比较排序。数学上证明,基于元素两两比较的排序,在最坏情况下的时间复杂度下界是 $O(n \log n)$。原因是 $n$ 个元素有 $n!$ 种可能的排列组合。每次比较只能排除一半的可能性。根据信息论,要确定唯一的正确序列,至少需要 $\log_2(n!)$ 次比较,而 $\log_2(n!)$ 约等于 $n \log_2 n$。
突破极限:非比较排序 $O(n)$
如果排序不依赖“两两比较”(例如计数排序、基数排序或桶排序),在特定条件下(如已知数值范围),复杂度可以达到惊人的 $O(n)$。但这类算法通常需要额外的内存空间,且对数据类型有严格限制(通常只能排整数)。
谁是最好的?
在真实世界的工业生产中,没有一种算法是全能的。因此,目前公认 “最好 ”的方案通常不是某个单一算法,而是混合算法(Hybrid Algorithms)。
(1) Timsort:现代语言的霸主
它是 Python、Java (Arrays.sort)、Android 和 Swift 默认的排序算法,底层是归并排序和插入排序的结合体。极度擅长处理现实世界中 “部分有序” 的数据。它会寻找数据中已经排好序的片段(Runs),然后巧妙地合并它们。它的性能和稳定性都极佳,时间复杂度能够稳定在 $O(n \log n)$,在处理几乎有序的数据时能达到 $O(n)$。
(2) Introsort(内省排序):C++ 的工业标准
C++ STL (std::sort) 使用的是这种算法。它是快速排序、堆排序和插入排序的三合一。开始使用快速排序(平均最快),如果递归深度太深(说明快排退化了),自动切换为堆排序(保证最坏也是 $O(n \log n)$)。当子数组变小时,切换为插入排序(处理小规模数据常数项更小)。
(3) 三路快排:处理重复元素的王者
正如上面我们给出的演示,在面对大量重复数据的特定场景下,三路快排的效率是无与伦比的。唯一的遗憾就是它是不稳定算法。
<img src=”/images/image-20260221162808820.png” alt=”主流排序算法”, style=”width:80%”>
为什么选Timsort?
你可能有疑问,为什么 Timsort 是大多数开发语言默认的排序算法?为什么它宁愿忍受一定的内存开销,也要坚持使用基于归并的逻辑,而不是像快速排序那样完全原地(In-place)交换?答案是:稳定性(Stability)。
归并排序是稳定的(相同元素的相对位置不变),而快速排序是不稳定的。在 Java、Python 这种面向对象的语言中,我们经常对复杂的对象数组进行排序(比如先按 “价格” 排,再按 “销量” 排)。如果排序算法不稳定,前一次排序的结果就会被破坏。为了绝对的稳定性,Timsort 认为牺牲一点点内存空间是完全值得的。另外:
- 临时空间并非 $O(n)$,而是 “按需分配”:Timsort 不会一上来就开辟一个和原数组一模一样的空间,它只会在合并两个已排序的片段(Run A 和 Run B)时,开辟一个等于其中较短片段长度的临时空间。
- Timsort 优先寻找数组中已经有序的片段(Runs),如果它发现两个相邻的片段已经自然衔接(比如前一段的最大值小于后一段的最小值),这时候它根本不会启动归并过程,也就完全不占用额外内存。
- 在现代计算机架构中,这种连续的小块内存分配和复制,由于受到 CPU 缓存(L1/L2 Cache)的加持,其速度往往比在超大数组中频繁进行随机的 “原地交换”(如快排)还要快。我们认为在内存开销和CPU开销之间选,我们更倾向于多用一点内存开销,而让腾出CPU去干更多的事。
最佳实践
在真实的生产环境中,没有人会只用一种算法到底。需要根据实际情况作出调整。
第一:优先调用系统原生函数
系统函数(如 Arrays.sort() 或 std::sort)几乎总是最优解。这些函数背后通常是 Timsort 或 Introsort。它们已经处理了所有极端的边界情况(有序、倒序、大量重复、小数据量),并且经过了高度的硬件指令集优化。
第二:根据数据规模选择
- $N < 16$ (小规模):直接用插入排序,小数组的 $O(n^2)$ 常数项极小,甚至比递归调用的开销还要低。
- $N$ 很大:使用混合排序(如 Timsort)。
第三:根据数据特征选择
- 数据中存在大量重复项:三路快排是绝对的杀手锏。
- 数据几乎已经有序:Timsort 或 插入排序,它们可以达到接近 $O(n)$ 的惊人效率。
- 数据量巨大,无法全部装入内存:必须使用多路归并排序(External Merge Sort)。
第四:根据业务需求(稳定性)选择
- 需要稳定性(例如:在已经按 “时间”排好序的订单中,再按 “金额” 排):必须选 Timsort 或 归并排序。
- 不需要稳定性且追求极致响应:选 快速排序 或 内省排序。