Zookeeper 的概述、安装和配置
概述
ZK是什么
Zookeeper 是一个开源的分布式的,为分布式应用提供协调服务的Apache项目。Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应,从而实现集群中类似Master/Slave管理模式。Zookeeper=文件系统+通知机制。
ZK的特点
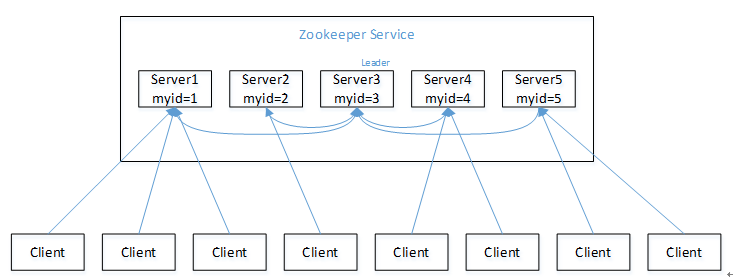
架构角色与职责:
- 一主多从:集群由一个 Leader 和多个 Follower 组成。
- Leader:集群的“大脑”,负责发起投票、处理写请求(更新系统状态)。
- Follower:负责处理读请求,并将写请求转发给 Leader;参与 Leader 选举和写请求的投票过程。
- Observer:不参与投票的 Followers。用于在不影响写性能的情况下,线性扩展集群的读性能。
存活与容错机制:
- 半数机制 (Quorum):集群只要有半数以上节点存活即可服务。
- 奇数部署 (Best Practice):
- 原因1:容错性价比。3 台和 4 台机器都只能挂 1 台,但 3 台更省资源。
- 原因 2:防止脑裂(Split-brain)。确保在网络分区时,只有一个分区能凑齐半数以上节点选出 Leader。
数据一致性保障:
- 全局数据一致 (Single System Image):每个 Server 内存中都维护着同样的数据树。无论 Client 连接哪台 Server,看到的视图基本一致。
- 原子性 (Atomicity):基于 ZAB 协议,一次更新要么全集群成功,要么全失败,没有中间状态。
- 实时性 (Eventual Consistency):ZK 保证的是最终一致性。Client 在极短时间内能读到最新数据(若需强一致读,需在读取前调用 sync())。
顺序性与并发控制 (核心亮点):
顺序性 (Sequential Consistency):
- 全局顺序:Leader 会为每个写请求分配一个全局唯一的递增事务 ID(zxid)。
- 客户端顺序:来自同一个 Client 的更新请求按其发送顺序执行。
乐观锁机制 :通过 dataVersion 实现,这是应用系统处理抢占式资源的基础。
内存级性能(High Throughput):
ZooKeeper 的全量数据都存储在内存中。
- 优点:读性能极高(QPS 可达数十万)。
- 代价:不适合存储大数据。单个 ZNode 数据上限默认为
1MB,通常建议保持在 1KB 以内。
临时节点与会话绑定(Ephemeral Nodes)
这是 ZK 实现分布式协调的杀手锏。
- 节点的生命周期与客户端的 Session 绑定。
- 应用掉线后,注册节点自动消失,实现自动化的服务剔除。
监听机制 (Watch Mechanism)
- 推拉结合。ZK Server 通知客户端 “数据变了”,客户端再主动来拉取。
- 极大地减少了客户端轮询对网络带宽的消耗,实现即时配置同步。
事务日志与快照(Persistence)
- 虽然数据在内存,但每一笔写操作都会先记录事务日志 (Transaction Log),并定期生成数据快照 (Snapshot)。
- 保证了服务器重启后数据能够 100% 恢复。
ZK节点及其类型
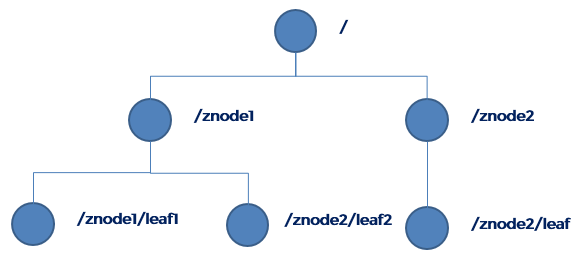
ZooKeeper数据模型的结构与Unix文件系统很类似,整体上可以看作是一棵树,每个节点称做一个ZNode。
每一个ZNode默认能够存储1MB的数据(这是官方要求。整个树状的目录结构全部都放在内存中提升吞吐效率),每个ZNode都可以通过其路径唯一标识。节点有两种类型:
短暂(ephemeral): 客户端和服务器端断开连接后,创建的节点自己删除持久(persistent): 客户端和服务器端断开连接后,创建的节点不删除
四种形式:
- 持久化目录节点(PERSISTENT) :客户端与 zookeeper 断开连接后,该节点依旧存在。
- 持久化顺序编号目录节点(PERSISTENT_SEQUENTIAL):客户端与 zookeeper 断开连接后,该节点依旧存在,只是 Zookeeper 给该节点名称进行顺序编号。
- 临时目录节点(EPHEMERAL):客户端与 zookeeper 断开连接后,该节点被删除。
- 临时顺序编号目录节点(EPHEMERAL_SEQUENTIAL):客户端与 zookeeper 断开连接后,该节点被删除,只是 Zookeeper 给该节点名称进行顺序编号。
关于有序节点:
- 创建 znode 时设置顺序标识,znode 名称后会附加一个值,顺序号是一个单调递增的计数器,由父节点维护
- 在分布式系统中,顺序号可以被用于为所有的事件进行全局排序,这样客户端可以通过顺序号推断事件的顺序
ZK的应用场景
提供的服务包括:
- 分布式API目录:典型的应用著名的Dubbo分布式框架就是应用了ZooKeeper分布式的JNDI能力。在Dubbo中,使用ZooKeeper维护全局的服务接口API地址列表。大致的思路为:
- 服务提供者(Provider)在启动的时候向ZK上的指定节点写 入自己的API地址,这个操作就相当于服务的公开。类似的API地址节点为:/dubbo/${serviceName}/providers
- 服务消费者(Consumer)启动的时候,订阅节 点/dubbo/{serviceName}/providers下的Provider服务提供者URL地 址,获得所有访问提供者的API。
- 分布式ID生成器:实际生产中为了防止zk压力过大,使用的是ID的分段机制,例如美团的 Leaf-ZK 方案,ZK 不负责生成每一个 ID,而是负责管理ID段。ZK存一个持久节点/id_generator,内容为1000。业务服务器 A 启动时,去 ZK 把这个值改为2000(利用 dataVersion 乐观锁确保安全),服务器 A 拿到了 1001~2000 这一千个 ID,在本地内存中利用 AtomicLong 自增分发,当服务器 A 这一千个 ID 用完了,再去 ZK 领下一批。当然也可以利用Redis的原子操作INCR和 INCRBY生成全局唯一的ID。
- 使用zk生成全局ID:千万不要用 ZK 的“顺序节点”直接生成每一个 ID,那会拖垮 ZK。ZK 仅作为“发号器”的管理者。每台业务服务器从 ZK 申请一个“号段”(如 1000~2000),然后由服务器在本地内存中通过 AtomicLong 自增。这种方式的优点是数据强一致(CP),ZK 的事务日志和过半协议保证了申请记录绝对不会丢失,ID 绝对不会重复,只要 ZK 集群半数以上存活,号段分发就不会停。但是这种方式复杂度也高,需要处理本地缓存用尽后的同步预取逻辑,如果号段设置不当,频繁访问 ZK 会产生性能瓶颈。比较适用于订单号、支付流水类的对重复ID零容忍的场景,强烈推荐
ZK + Snowflake (最强结合)。 - 使用Redis的原子操作INCRs生成全局ID:优点是性能极高,纯内存操作,单机支撑万级甚至十万级 QPS 毫无压力,开发也简单,几行代码即可实现。Redis 默认的 RDB 持久化会丢失几分钟数据,即使开启 AOF(建议设置 everysec),在极端宕机情况下仍可能丢失 1 秒的数据,从而导致 ID 重复。比较适用于点赞数、短链接、非核心流水号等场景。
- 使用zk生成全局ID:千万不要用 ZK 的“顺序节点”直接生成每一个 ID,那会拖垮 ZK。ZK 仅作为“发号器”的管理者。每台业务服务器从 ZK 申请一个“号段”(如 1000~2000),然后由服务器在本地内存中通过 AtomicLong 自增。这种方式的优点是数据强一致(CP),ZK 的事务日志和过半协议保证了申请记录绝对不会丢失,ID 绝对不会重复,只要 ZK 集群半数以上存活,号段分发就不会停。但是这种方式复杂度也高,需要处理本地缓存用尽后的同步预取逻辑,如果号段设置不当,频繁访问 ZK 会产生性能瓶颈。比较适用于订单号、支付流水类的对重复ID零容忍的场景,强烈推荐
分布式节点的命名:一个分布式系统通常会由很多节点组成,而且节点的数量不是固定的,是不断动态变化的。比如当业务不断膨胀和流量洪峰到来时,可能会动态加入大量的节点到集群中。一旦流量洪峰过去,就需 要下线大量的节点。再比如说,由于机器或者网络的原因,一些节点会主动离开集群。如何为大量的动态节点命名呢?一种简单的办法是,通过配置文件手动进行每一个节点的命名。如果节点数据量太大,或者说变动频 繁,手动命名是不现实的,这就需要用到分布式节点的命名服务。
统一配置管理:将配置信息配置到zk某个目录下,监听者监听配置信息是否发生变化,若发生变化则立刻同步
- 软负载均衡:存储每个每个服务节点的访问数,进行软负载均衡
- 分布式锁:获取 xxx/locknode下的有序节点列表,判断自己创建的节点是否是序号最小的,是则获取锁,否则监听比自己小一号的节点。
- 优点:ZooKeeper分布式锁(如InterProcessMutex)能有效地解决分布式问题、不可重入问题,使用起来较为简单。
- 缺点:ZooKeeper实现的分布式锁性能不太高。因为每次在创建锁和释放锁的过程中都要动态创建、销毁瞬时节点。在 ZooKeeper中,创建和删除节点只能通过Leader服务器来执行, 然后Leader服务器还需要将数据同步到所有的Follower机器 上,这样频繁的网络通信,性能的短板是非常突出的。
- 在高性能、高并发的场景下,不建议使用ZooKeeper的分布式锁。由于ZooKeeper具有高可用特性,因此在并发量不是太高的场景推荐使用ZooKeeper的分布式锁。
ZKLeader的选举机制
核心选举指标
简单说就是这个 Epoch, ZXID, SID 三元组。当服务器处于 LOOKING 状态时,每台机器都会发出一个投票(Vote),这个投票本质上是一张名片,上面写着:我的逻辑时钟,我的数据 ID,我的服务器 ID。以下是选举权重的优先级排位:
- 逻辑时钟 (Epoch/Election Epoch):最高优先级。 就像选票的“版本号”。如果你的投票版本比我旧,我直接不理你;如果你的比我新,我立刻更新自己的版本并听你的。
- 数据 ID (ZXID):第二优先级。 谁的 ZXID 越大,说明谁持有的数据越新。数据更新、最全的服务器理应更有资格当 Leader(保证 CP 系统的强一致性)。
- 服务器 ID (SID):最后的底牌。 如果大家的逻辑时钟和数据版本都一模一样(通常是刚开机时),那就看 SID,数字大的赢。
选举状态机
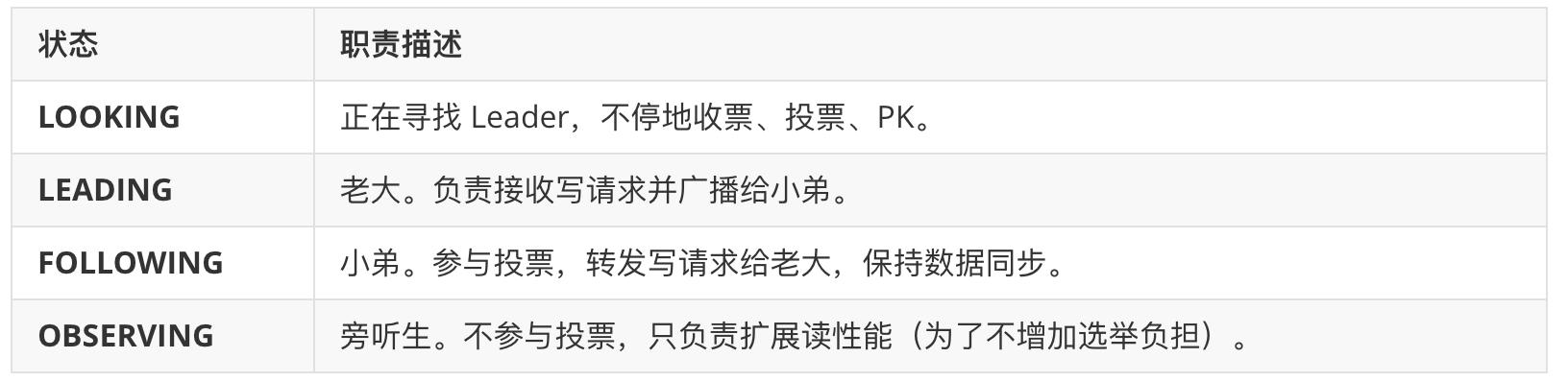
在选举过程中,每个节点都在以下四个状态间切换:
选举场景
场景一:集群启动(白手起家)
假设有 3 台服务器(SID 为 1、2、3),按顺序启动:
- Server 1 启动:给自己投一票。目前票数 $1/3$,没过半,状态为 LOOKING。
- Server 2 启动:给自己投一票,并与 Server 1 交换信息。
- PK 开始:Server 2 发现自己的 SID (2) > Server 1 的 SID (1)。
- 结果:Server 1 “认输”,改投 Server 2。
- 统计:Server 2 现在有 2 票(自己的一票 + 1 的一票),超过半数 (2/3)!
- 定局:Server 2 成为 LEADING,Server 1 变为 FOLLOWING。
- Server 3 启动:发现江湖已有老大(Server 2),直接认怂,变为 FOLLOWING。
场景二:运行中 Leader 宕机(中途换届)
这是最体现 ZXID 价值的时候。假设 Leader (Server 2) 突然挂了:
- 状态切换:Server 1 和 Server 3 发现 Leader 失联,立即将状态改为
LOOKING。 - 亮底牌:Server 1 发出 (Epoch=2, ZXID=100, SID=1);Server 3 发出 (Epoch=2, ZXID=105, SID=3)。
- PK 结果:虽然 Server 3 的 SID 大,但核心胜出点在于 ZXID (105 > 100)。这意味着 Server 3 掌握了更多尚未同步的事务。最终 Server 3 毫无疑问成为新 Leader。
ZK的安装配置和常用命令
ZK的安装和配置
在安装 ZK 之前,请确保基础环境就绪:
- JDK:建议安装 JDK 17(ZK 3.8 对高版本支持很好)。
- 防火墙:确保三台机器之间 2181(客户端连接)、2888(集群内通信)、3888(选举专用)端口互通。
- 用户:建议创建专门的 zookeeper 用户,避免使用 root 运行。
1 | $ tar -zxvf /opt/apache-zookeeper-3.8.6-bin.tar.gz |
生产级配置文件 /opt/zookeeper/conf/zoo.cfg
1 | # 基础心跳配置 |
VM 参数调优 (java.env):在 conf 目录下新建 java.env 文件。ZK 是内存敏感型组件,必须锁定堆内存避免 Swap。
1 | # 假设你的服务器是 8G 内存,建议分配 2-4G 给 ZK |
依次在三台机器上启动:
1 | $ systemctl stop firewalld |
常用客户端命令
1 | # 客户端连接与管理 |
节点操作基础
1 | # 创建节点 |
ZK权限管理(ACL)
传统的文件系统中,ACL分为两个维度,一个是属组,一个是权限,子目录/文件默认继承父目录的ACL。而在Zookeeper中,node的ACL是没有继承关系的,是独立控制的。Zookeeper的ACL,可以从三个维度来理解:一是scheme; 二是user; 三是permission,通常表示为 scheme:id:permissions, 下面从这三个方面分别来介绍:
- scheme:zk3 缺省支持下面几种scheme:
- ip:它对应的id为客户机的IP地址,设置的时候可以设置一个ip段,比如ip:192.168.1.0/16, 表示匹配前16个bit的IP段
- digest:它对应的id为username:BASE64(SHA1(password)),它需要先通过username:password形式的authentication
- auth:它不需要id, 只要是通过authentication的user都有权限(zookeeper支持通过kerberos来进行authencation, 也支持username/password形式的authentication)
- super:在这种scheme情况下,对应的id拥有超级权限,可以做任何事情(crwda)
- world:它下面只有一个id, 叫anyone, world:anyone代表任何人,zookeeper中对所有人有权限的结点就是属于world:anyone的
- sasl:zk3还提供了对sasl的支持,不过缺省是没有开启的,需要配置才能启用。sasl的对应的id,是一个通过sasl authentication用户的id,zk3中的sasl authentication是通过kerberos来实现的,也就是说用户只有通过了kerberos认证,才能访问它有权限的node.
- id:id与scheme是紧密相关的,具体的情况在上面介绍scheme的过程都已介绍,这里不再赘述。
- permission:zookeeper目前支持下面一些权限
- CREATE(c): 创建权限,可以在在当前node下创建child node
- READ(r): 读权限,可以获取当前node的数据,可以list当前node所有的child nodes
- WRITE(w): 写权限,可以向当前node写数据
- DELETE(d): 删除权限,可以删除当前的node
- ADMIN(a): 管理权限,可以设置当前node的permission
1 | #创建数据节点时设置acl |
ZK的监听原理
传统监听机制

传统监听机制的三大核心特性:
- 一次性触发:无论是 get -w 还是 ls -w,一旦数据发生变化,ZooKeeper 就会向客户端发送一个通知,然后该 Watcher 就会被立即从服务端的注册列表中删除。如果你想持续监听,必须在处理完事件后手动重新注册。
- 轻量级通知:ZooKeeper 的通知非常吝啬,它只会告诉你数据变了或子节点变了,但不会告诉你具体变成了什么。客户端收到通知后,必须再次发起一次请求(如 get)才能拿到新数据。
- 客户端串行执行:客户端的 process() 方法是由一个专门的 EventThread 调用的。这意味着如果你在 process() 里写了耗时很长的逻辑(比如复杂的业务计算或阻塞 IO),会卡死所有的监听回调。
监听的整个流程:
- 第一阶段:注册(逻辑上的“标记”)。客户端调用 getData(“/path”, true),请求发给 ZK Server,Server 会在对应的 ZNode 上记录下 “Session ID 为 0x123 的哥们想看这个节点的变化”。
- 第二阶段:触发(服务端的“广播”)。另一个客户端修改了 “/path” 的数据。ZK Server 检查这个路径上的监听列表,发现 0x123 注册过。Server 发送一个 WatchedEvent 给客户端。发送完后,Server 会立刻把 0x123 从这个路径的监听名单中踢出去。
- 第三阶段:回调(客户端的“反应”)。客户端的 SendThread 接收到事件,将其放入 EventQueue。EventThread 从队列里取出事件,执行你写的 process()。
新增的 addWatch
新增的addWatch (3.6+) 改变了游戏规则,它是对你图中传统监听模式的重大升级:
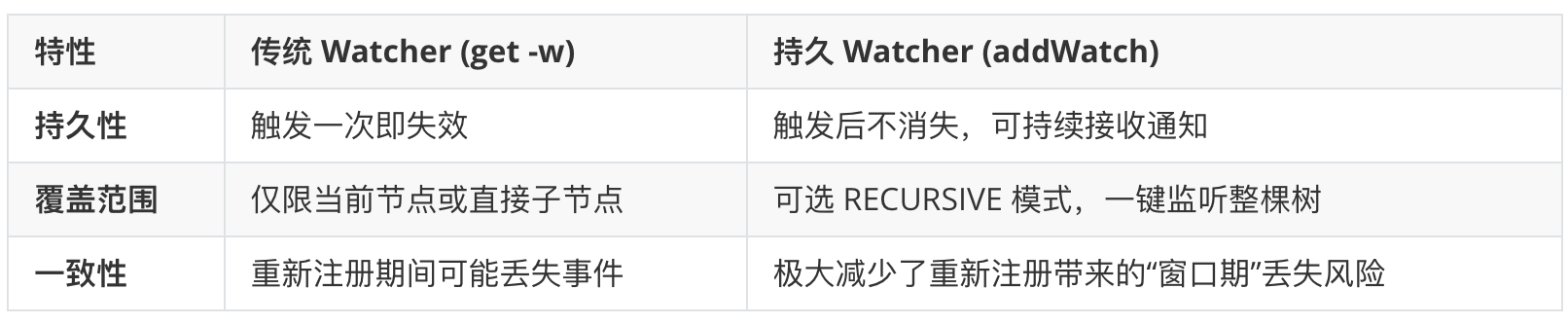
在传统模式下,你收到通知 $\rightarrow$ 调用 get 获取数据 $\rightarrow$ 顺便再次注册。在“收到通知”和“再次注册”之间有一个微小的时间空隙。如果在这个瞬间数据又变了,你是收不到第二次通知的。重要业务(如集群配置)务必使用 addWatch 的持久模式。
ZK写数据的流程
写数据的过程
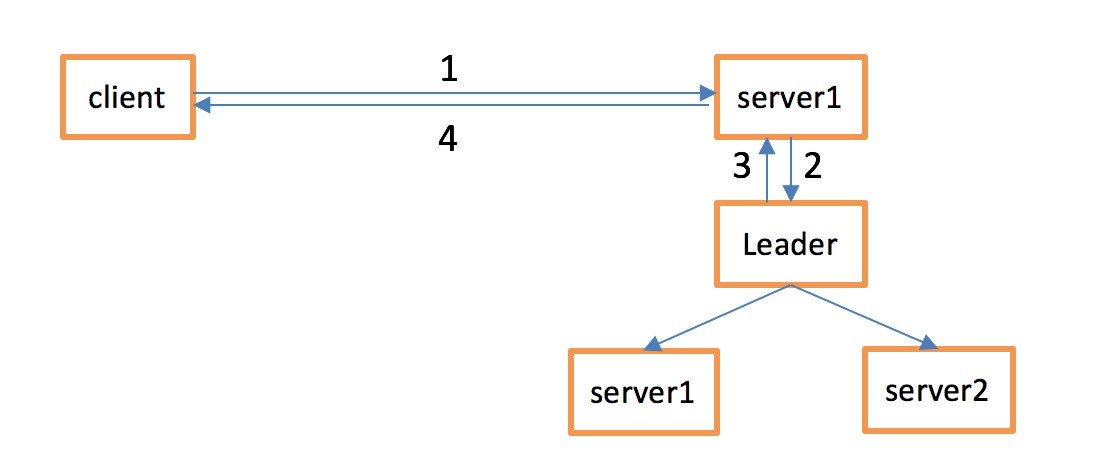
从 CAP 定理的角度来看,ZooKeeper 是典型的 CP 系统(强一致性 + 分区容错性)。
- Client 向 ZooKeeper 的 Server1 上写数据,发送一个写请求。
- 如果Server1不是Leader,那么Server1 会把接受到的请求进一步转发给Leader,因为每个ZooKeeper的Server里面有一个是Leader。
这个Leader 会将写请求广播给各个Server,比如Server1和Server2,各个Server写成功后就会通知Leader。 - 当Leader收到大多数 Server 数据写成功了,那么就说明数据写成功了。如果这里三个节点的话,只要有两个节点数据写成功了,那么就认为数据写成功了。写成功之后,Leader会告诉Server1数据写成功了。
- Server1会进一步通知 Client 数据写成功了,这时就认为整个写操作成功。ZooKeeper 整个写数据流程就是这样的。
关于写的过程,在生产环境下,还有两个关键点决定了 ZK 的写性能:
- 事务日志与快照(The WAL):当 Server1、Server2 收到 Leader 的写请求时,它们并不是直接写到内存就完了。每个 Server 必须先将这个写操作记录到事务日志(Transaction Log)中并持久化。只有磁盘写入成功后,才会给 Leader 发 ACK。这就是为什么我们之前建议你将 ZK 的 dataLogDir 放在独立 SSD 上的原因——磁盘 IO 的快慢直接决定了你写数据的延迟。
- 两阶段提交(Two-Phase Commit, 2PC):ZK 的写流程实际上是一个简化的 2PC。第一阶段 (Proposal) 是 Leader 发起提议,询问大家能不能写。第二阶段 (Commit) 是半数以上回复 OK 后,Leader 再次广播 Commit 指令,所有人正式提交。
为什么 ZK 选择 CP?
在分布式系统的三要素中,ZooKeeper 的取舍如下:
- Consistency (一致性 - C): ZK 追求的是最终一致性(严格来说是顺序一致性)。Leader 必须收到半数以上(Quorum)节点的确认(ACK)才会提交事务。这意味着任何时刻,只要集群正常工作,你读到的数据要么是最新的,要么是正在同步中的,绝不会出现长期的逻辑冲突。
- Partition Tolerance (分区容错性 - P): 这是分布式系统的底线。在网络发生分区时(比如 149 和 166、224 断开),ZK 集群必须能继续生存。
- Availability (可用性 - A) - 被牺牲项: 这是 ZK 最被外界“诟病”但也最自豪的地方。在 Leader 选举期间,整个 ZK 集群是不可用的。如果我们的 149(Leader)宕机了,166 和 224 会立即开始选举。在选举出新 Leader 之前的几十秒内,集群不接受任何读写请求。为了保证数据绝对不错,它宁愿暂时“罢工”。
ZK的读性能
虽然说 ZK 是 CP,但它的读操作非常快,甚至表现得像 AP,因为 Client 连接到哪个 Server,就从哪个 Server 直接读数据,不需要经过 Leader。这导致了 ZK 的读是 “模糊” 的。如果 Leader 刚写完,但同步给 Server2 的包还在路上,你从 Server2 读到的可能是旧值。如果你在代码中要求必须读到最新值,需要在读之前先调用 sync() 命令。